开始使用
DataSpell 是一个集成开发环境(IDE),专注于探索性数据分析和原型化机器学习(ML)模型的特定任务。 您可以从 https://www.jetbrains.com.cn/dataspell/ 下载它。
确保您已准备就绪
在开始之前,请检查所有必需的软件是否适用于您的环境并已安装在您的计算机上。
支持的语言
要在 DataSpell 中开始开发,您需要从 python.org 下载并安装 Python,并从 https://cran.r-project.org/ 下载并安装 R。
DataSpell 支持以下版本:
Python 2: 版本 2.7
Python 3: 从 3.9 版本到 3.14 版本
R :3.4 及更高版本。
支持的平台
DataSpell 是一个跨平台的 IDE,可在 Windows、macOS 和 Linux 上运行。 检查系统要求:
要求 | 最低 | 推荐 |
|---|---|---|
内存 | 2 GB 的可用内存 | 8 GB 的系统总内存 |
处理器 | 任何现代处理器 | 多核 CPU。 DataSpell 支持多线程进行不同的操作和处理,使其能够使用更多的 CPU 核心时速度更快。 |
磁盘空间 | 3.5 GB | 至少有 5 GB 可用空间的 SSD 硬盘 |
显示器分辨率 | 1024×768 | 1920×1080 |
操作系统 | 以下产品的正式发布版本:
不支持预发布版本。 | 以下内容的最新版本:
|
如果您需要安装 DataSpell 的帮助,请参阅 安装说明。
安装 Conda
如果您计划使用 Conda 环境:
找到您的方向
当您 运行 DataSpell 时,它会显示 欢迎屏幕 ,这是您使用 IDE 并配置其设置的起点。
首次运行 DataSpell 时,您可以选择以下选项之一:
快速开始
DataSpell 工作区已打开。 您可以将目录和项目以及 Jupyter 连接添加到工作区。
有关更多信息,请参阅 快速开始。
项目
如果您想处理项目,请选择此选项。 您可以从磁盘或 VCS 打开现有项目,也可以创建新项目。
有关更多信息,请参阅 在 DataSpell 中处理项目 。
您可以将 本地笔记本 和数据集添加到工作区, 附加目录 ,并从版本控制系统 克隆项目。
了解主要 UI 元素:

有关更多信息,请参阅 用户界面。
使用笔记本
在 DataSpell 中,您可以轻松编辑、执行并检查执行输出,包括流数据、图像和其他媒体。 以下是一个典型的工作流程:
创建一个 notebook 文件
请执行以下操作之一:
在 工作区 工具窗口中右键单击目标目录,然后从上下文菜单中选择 新建。
请按 Alt+Insert
请选择 Jupyter Notebook。
在打开的对话框中,输入文件名, 示例 。

笔记本文档具有 *.ipynb 扩展名,并标有相应的图标:
 。
。新创建的笔记本将在编辑器中打开。 它包含一个代码单元格。 您可以使用笔记本工具栏中的单元格类型选择器更改其类型:

编辑笔记本
要编辑单元格,只需单击它。
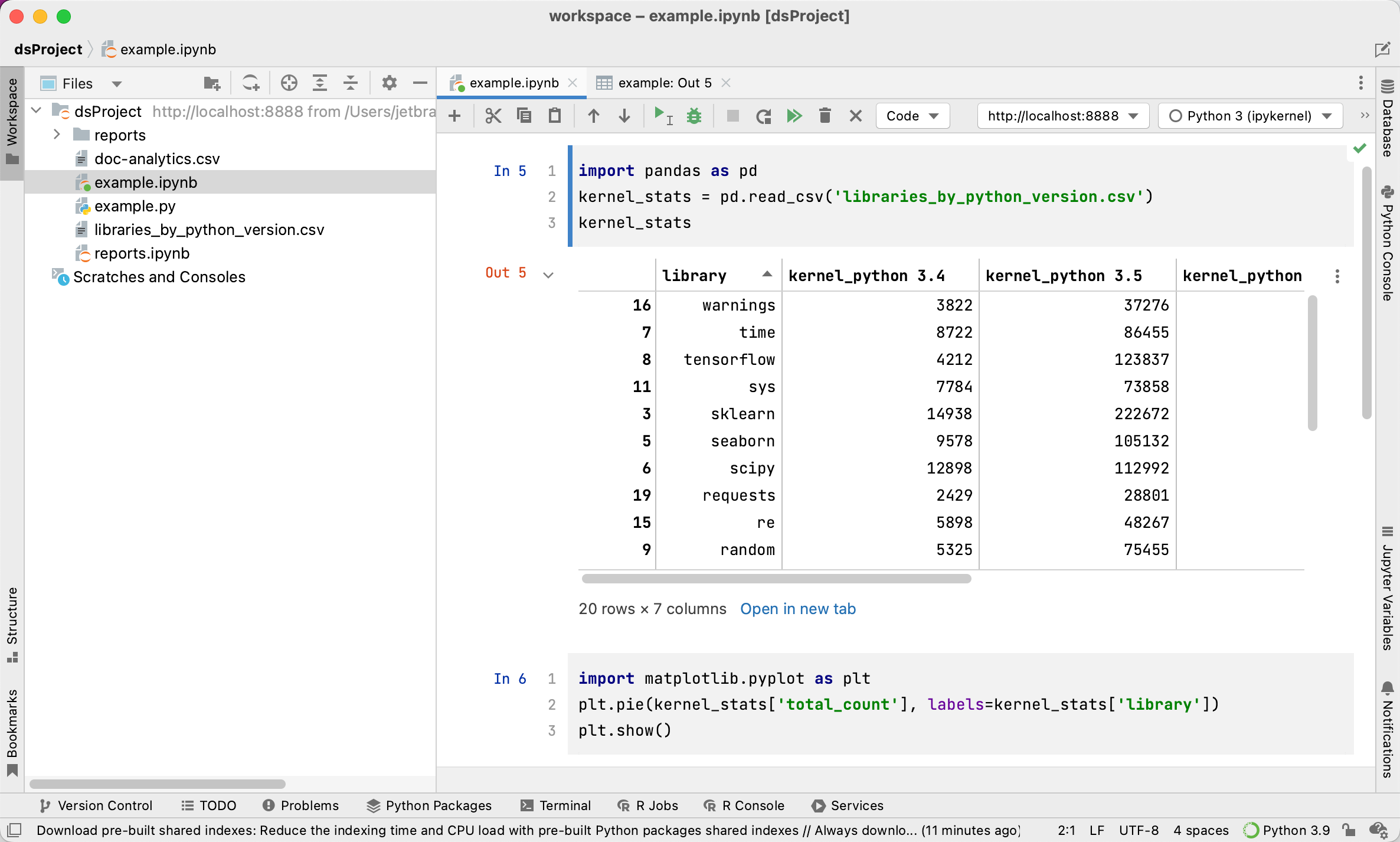
在第一个代码单元格中输入一些 pandas 代码:
import pandas as pd kernel_stats = pd.read_csv('libraries_by_python_version.csv') kernel_stats您无需提前安装
pandas软件包。 只需单击高亮行,按 Alt+Enter ,并选择缺少的导入语句的建议修复。此示例使用 libraries_by_python_version.csv 数据集。 从 libraries_by_python_version.csv 下载并保存到项目目录中。
向笔记本中添加更多代码或 Markdown 单元格。 您可以在最后一个单元格之后添加代码单元格,在选定单元格之后添加代码单元格或 Markdown 单元格,或者在执行选定单元格后插入新单元格。 您可以在 主菜单项中找到这些操作。
让我们输入一些
matplotlib代码来可视化第一个代码单元格的数据框。import matplotlib.pyplot as plt plt.pie(kernel_stats['total_count'], labels=kernel_stats['library']) plt.show()
同样,无需预先安装
matplotlib和numpy。 使用 Alt+Enter 修复导入。
您可以借助 代码洞察 (如 语法高亮 、代码 补全 等)编辑代码单元格。

执行笔记本
您可以通过多种方式执行笔记本单元格的代码,使用 Jupyter 笔记本工具栏上的图标、代码单元格上下文菜单的命令(右键单击代码单元格以打开)以及主菜单中的 命令。
一旦您执行了单元格,其输出将显示在代码下方。 您可以单击 在新选项卡页中打开 在编辑器的单独选项卡中预览表格数据。

请注意,当您使用本地笔记本时,无需提前启动任何 Jupyter 服务器:只需执行任意单元格,服务器将会启动。
Jupyter 工具窗口显示执行状态。 变量 选项卡中显示变量的当前值。 您可以在 Jupyter 变量 工具窗口中预览代码中声明的变量。
现在执行第二个单元格。 其代码依赖于第一个单元格中的变量,因此单元格执行的顺序很重要。

您可以复制生成的图表或将其保存为图像。 要执行所有单元格,请单击笔记本工具栏上的
 。
。
Debug
单击编辑器中最左侧的空白区域(gutter)以在选定单元格中设置断点。
在 Windows/Linux 上按 Shift+Alt+Enter 或在 macOS 上按 ⌥⇧⏎ 。 要调试整个笔记本,请从主菜单中选择 。

使用单步调试工具栏按钮选择下一步要停止的行,并切换到 调试器 工具窗口以预览变量值。

管理连接
您可以在不同的服务器和内核上运行笔记本。 您可以使用两种类型的 Jupyter 服务器:已配置和托管:
托管 服务器由 DataSpell 为当前项目自动启动。 当您关闭 DataSpell 时,它们会被终止。
已配置 服务器。 您通过指定其 URL 和令牌连接到这些服务器。 您可以连接到 本地 或 远程 Jupyter 服务器。
配置服务器
当您启动任何 Jupyter 服务器时,默认情况下它使用当前项目解释器和自动选择的端口。 但是,您可以选择 DataSpell 实例中可用的任何其他解释器并指定备用端口。 您还可以连接到任何已配置的服务器,只要您知道其 URL 和令牌。
要打开服务器设置,请在 Jupyter 笔记本工具栏上的 Jupyter 服务器列表中选择 配置 Jupyter Server。

要连接到任何正在运行的 Jupyter 服务器,请选择 配置的服务器 并指定服务器的路径,包括 URL 和令牌。
在 Jupyter 工具栏中,从服务器列表中选择 切换到当前的 Jupyter 服务器 以显式切换到已配置的服务器。
详情请参见 管理 Jupyter notebook 服务器。
调整您的工作环境
要在笔记本中执行 Python 代码,需要基于 Python 解释器的虚拟环境。 因此,您需要在您的计算机上至少配置一个环境。
当您在 DataSpell 中打开一个现有项目或连接到 Jupyter 服务器时,IDE 会为您创建一个虚拟环境。 在大多数情况下,这是基于您的 Anaconda 安装的 Conda 环境。 您可以选择计算机上的任何其他 Conda 环境或创建一个新环境。
更改您的环境
使用位于 DataSpell UI 右下角的 Python 解释器选择器更改环境。 单击它并从列表中选择目标环境。

使用 Anaconda CLI 更改 Conda
在 终端 窗口中,在 <Conda Home>/envs 目录中运行
ls命令(例如, /Users/jetbrains/.conda/envs ),并选择目标环境。导航到您的 anaconda 安装的 bin 目录(例如, anaconda3/bin )。
执行
conda activate <env name> command(例如,conda activate my-conda-env)。
创建一个新环境
在 Python 解释器选择器中选择 添加解释器。
在 添加Python 解释器 对话框中,输入新环境的名称,并在 Conda 可执行文件字段中指定 Anaconda 基础。

基于同一 Anaconda 安装创建多个 Conda 环境的原因显而易见——您可以为每个环境安装特定的包,并将它们用于特定的任务和项目。 您还可以选择其他类型的环境,例如 venv 或 pipenv。
安装软件包
在 Python 解释器选择器中,选择目标环境并选择 解释器设置。

单击
 添加新包。 单击 Conda 包管理器 按钮(
添加新包。 单击 Conda 包管理器 按钮( )以管理来自 Conda 仓库的软件包。 否则,DataSpell 将使用 pip。
)以管理来自 Conda 仓库的软件包。 否则,DataSpell 将使用 pip。在 搜索 字段中输入软件包名称并定位目标软件包。 如果需要,指定包版本。
点击 安装。 任务完成后关闭窗口。
更进一步
R 语言
在 DataSpell 中安装 R 插件 后,您可以使用 R 语言 执行各种统计计算,并使用代码辅助、可视化调试、智能运行和预览工具以及其他流行的 IDE 功能。

数据库
您可能已经注意到,创建各种类型的项目需要数据源。 也很可能您会将 SQL 语句注入到源代码中。
DataSpell 不支持创建数据库,但提供了管理和查询数据库的功能。 一旦您获得对某个数据库的访问权限,您可以在 DataSpell 中配置一个或多个数据源,这些数据源反映数据库的结构并存储数据库访问凭据。 基于这些信息,DataSpell 建立与数据库的连接,并提供检索或更改其中包含的信息的能力。
数据库的访问由 数据库窗口 ( )提供。 此工具窗口允许您处理数据库。 它使您能够查看和修改数据库中的数据结构,并执行其他相关任务。

有关更多信息,请参阅 数据库工具和 SQL。