DataGrip 2024.1 最新变化
DataGrip 2024.1 现已发布! 2024 年的首个重大升级包含众多改进。 我们来一起了解一下所有新功能和更新吧!
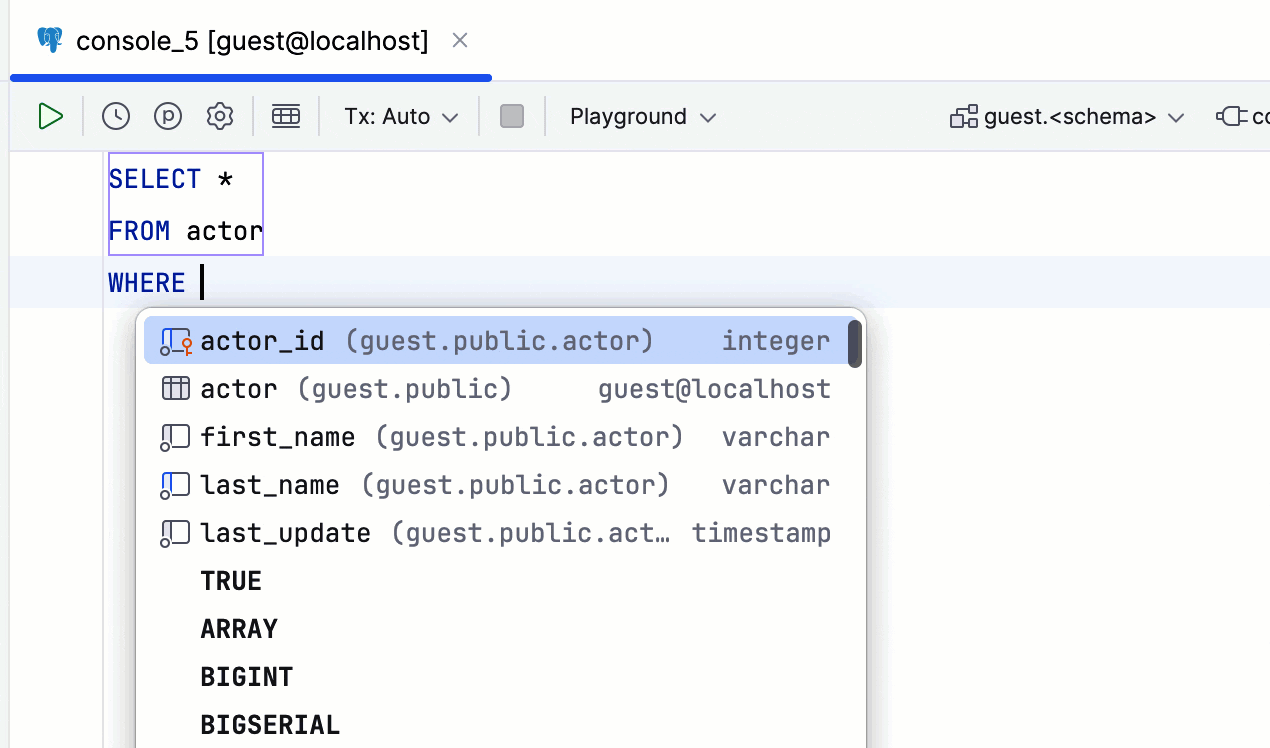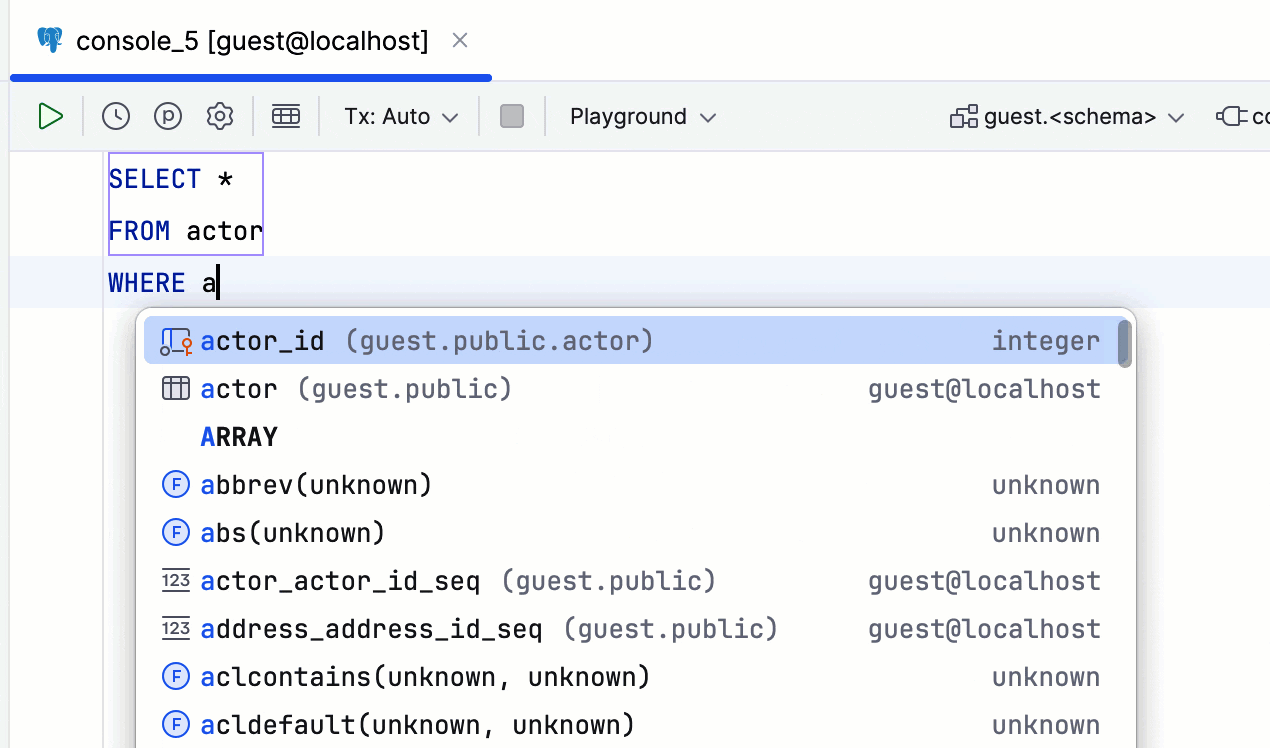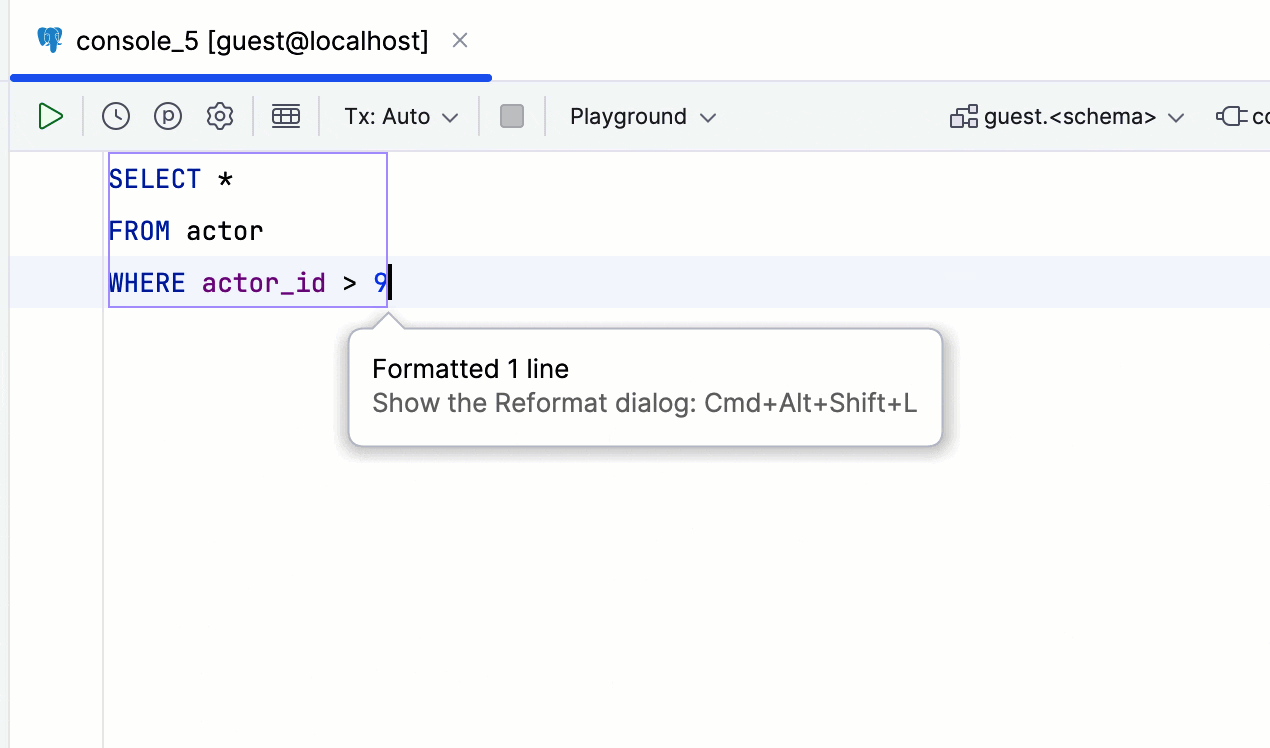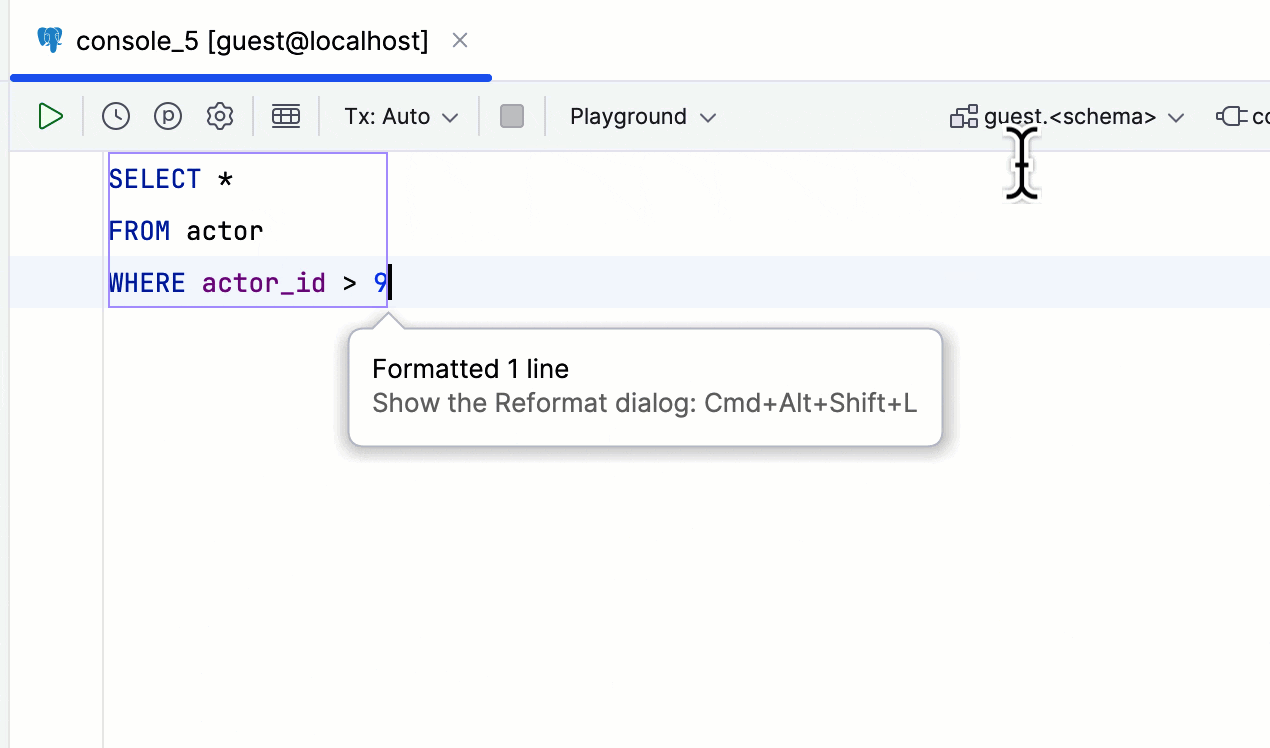
AI Assistant:附加架构的选项 仅限 DataGrip
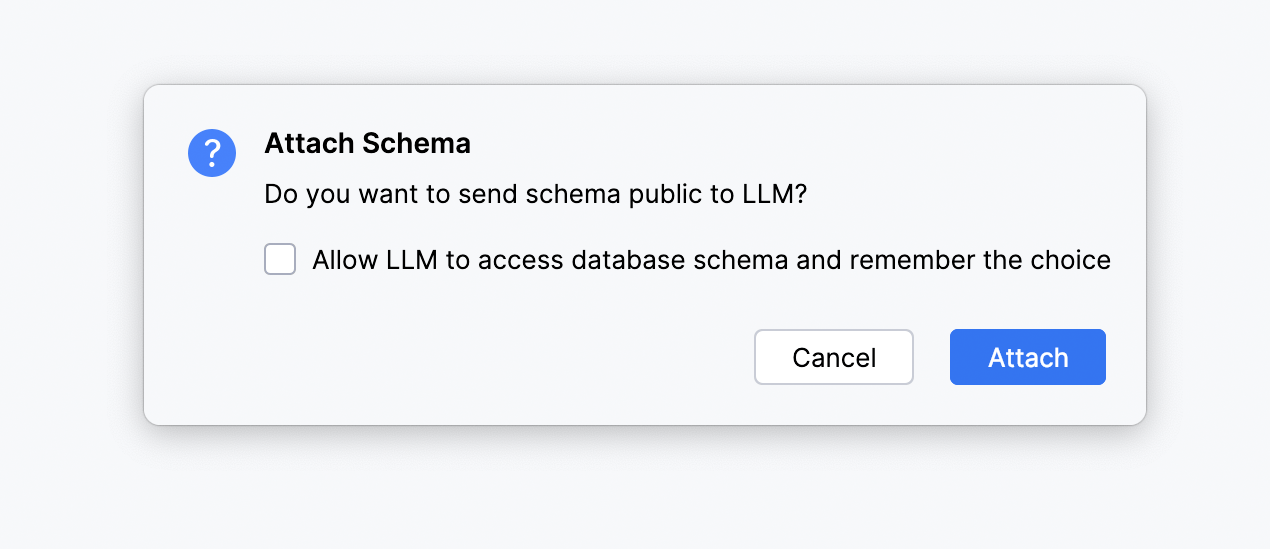
AI Assistant 现在允许您通过向聊天附加数据库架构上下文来提高生成的 SQL 查询的质量。 目前,仅可附加表名和列名,上限为 50 个表。
要使用此功能,您需要允许 AI Assistant 在您的项目中搜索数据库对象。
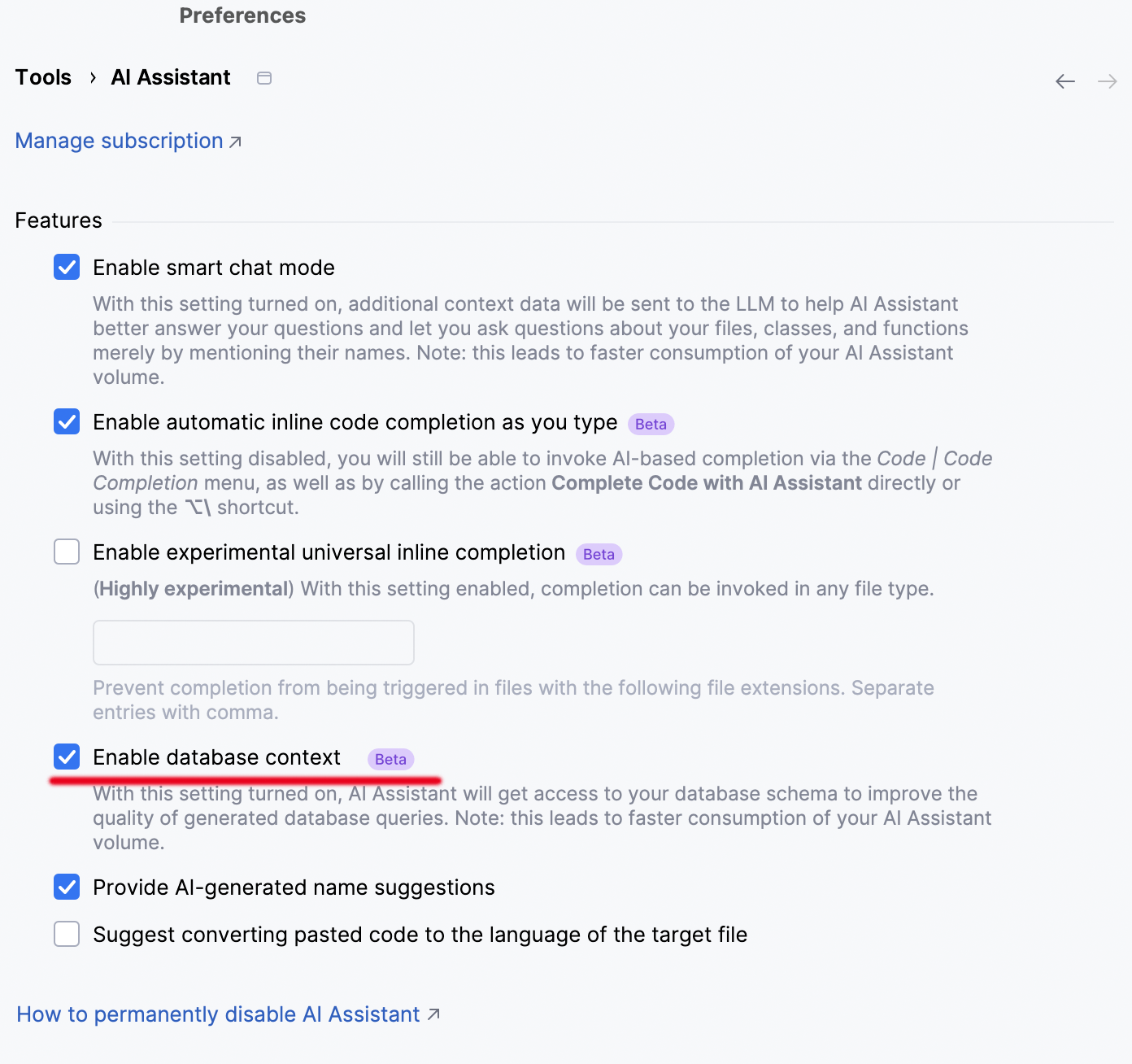
您可以在每次附加新架构时执行此操作,也可以勾选 Attach Schema(附加架构)弹出窗口中的选项,让 AI Assistant 记住您的选择。 在这种情况下,Enable database context(启用数据库上下文)设置将自动打开:
重要提示:勾选 Enable database context(启用数据库上下文)设置后,AI Assistant 将可以访问所有数据源中的所有对象名称。
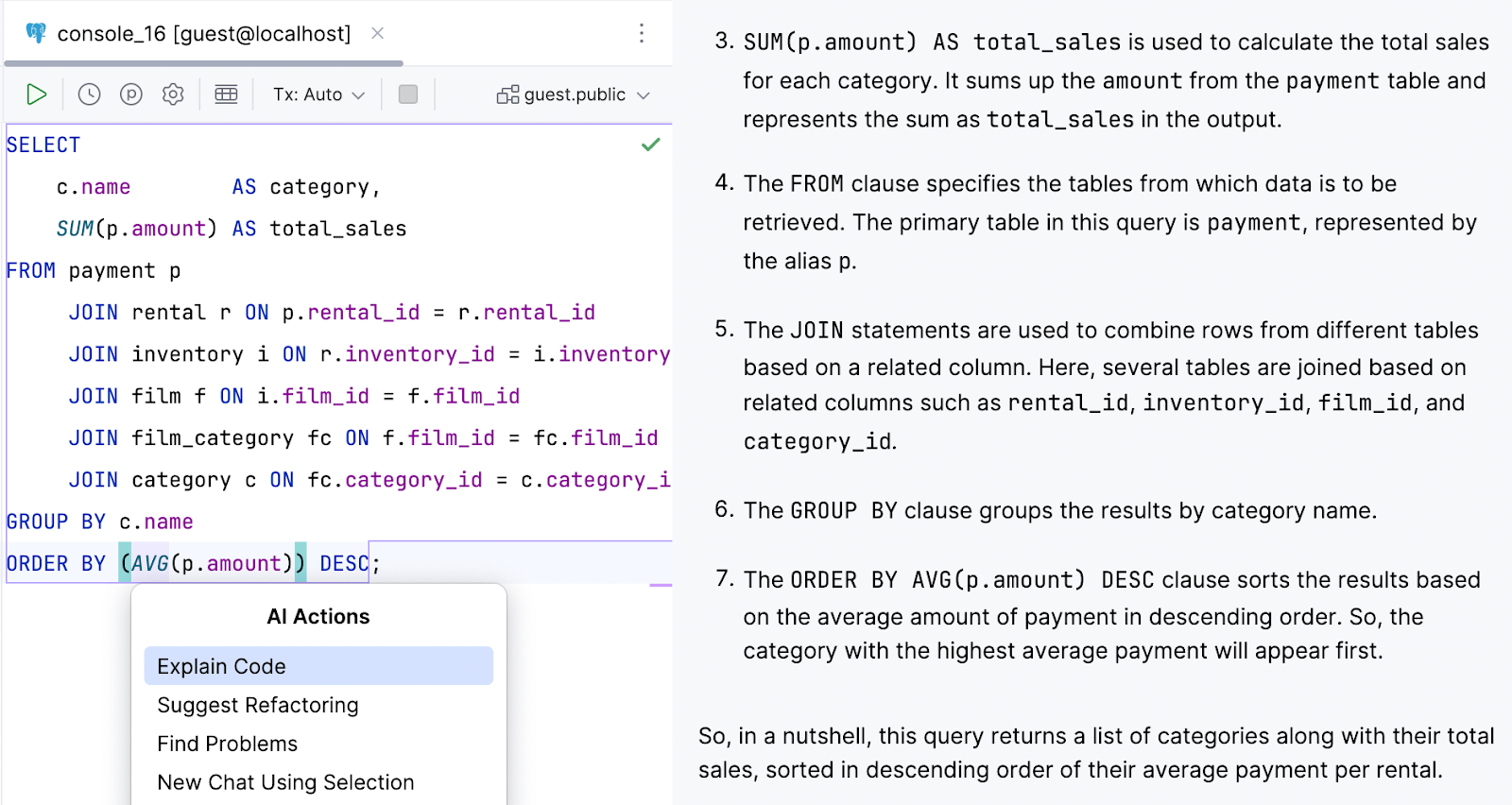
现在,Explain Code(解释代码)等编辑器内上下文菜单功能在从数据库控制台调用时可以了解当前架构。

由于 AI Assistant 能够识别您的架构,您可以:
- 从自然语言请求生成查询:

- 获取架构洞察:

- 执行不常用搜索:
以上只是部分示例, 您可以探索无限的可能性!
处理数据
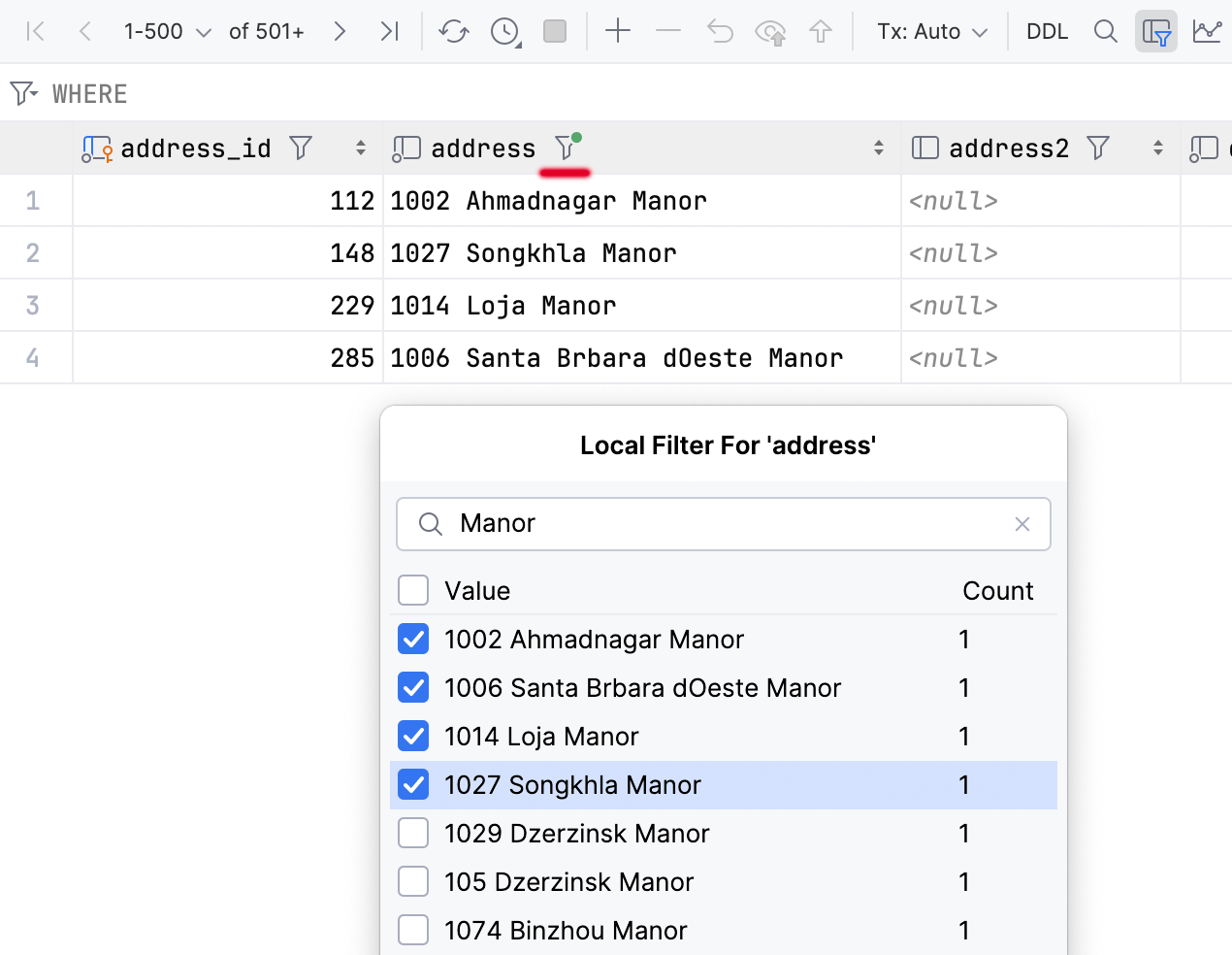
数据编辑器中的本地筛选器
备受期待的功能终于到来:您现在可以按列中的值筛选行。
这种方式速度很快,因为它不涉及向数据库发送查询。 但值得注意的是,筛选只会影响当前页面。 因此,如果您想筛选更多信息,只需更改页面大小或提取所有数据。
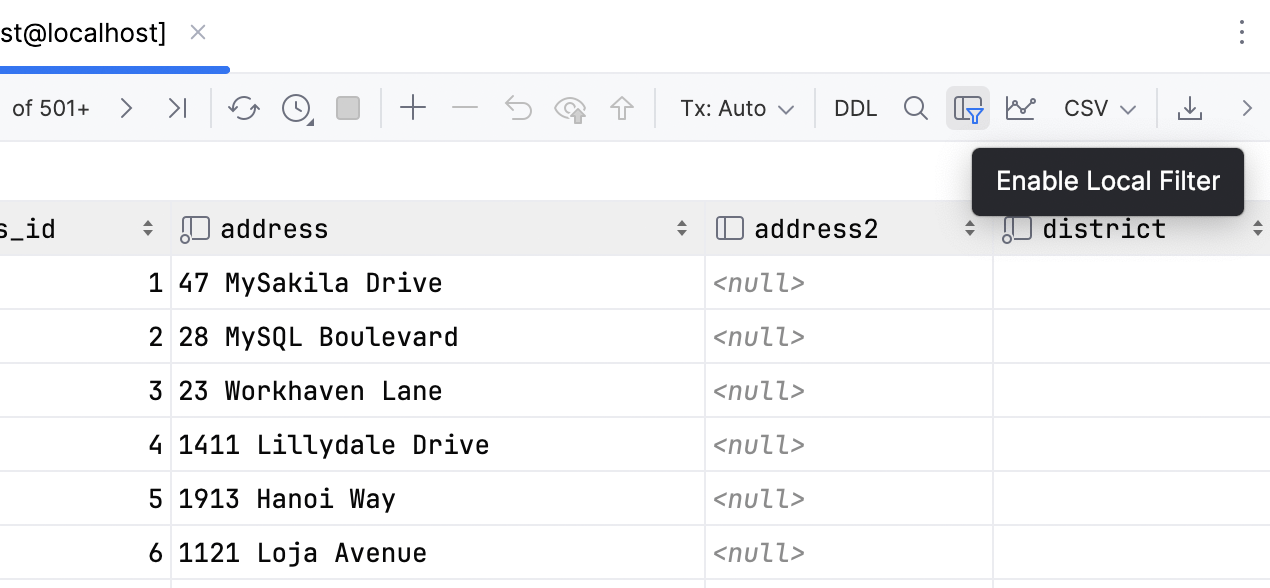
如果您想关闭当前数据编辑器的所有本地筛选器,请取消选择 Enable Local Filter(启用本地筛选器)按钮  。
。
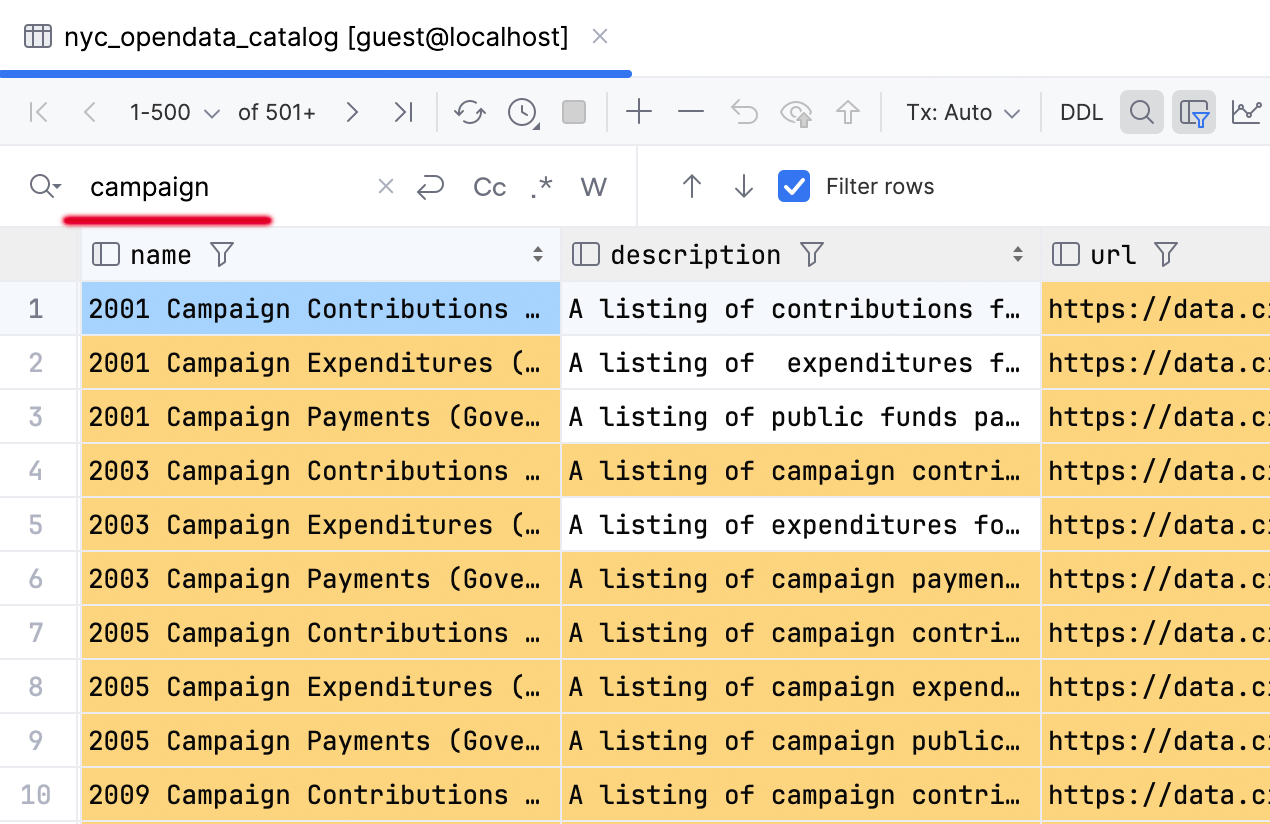
别忘了本地文本搜索功能 (Ctrl/Cmd+F)! 它已经存在了几十年,而且仍然实用,可以帮助您大致了解搜索的数据的位置。
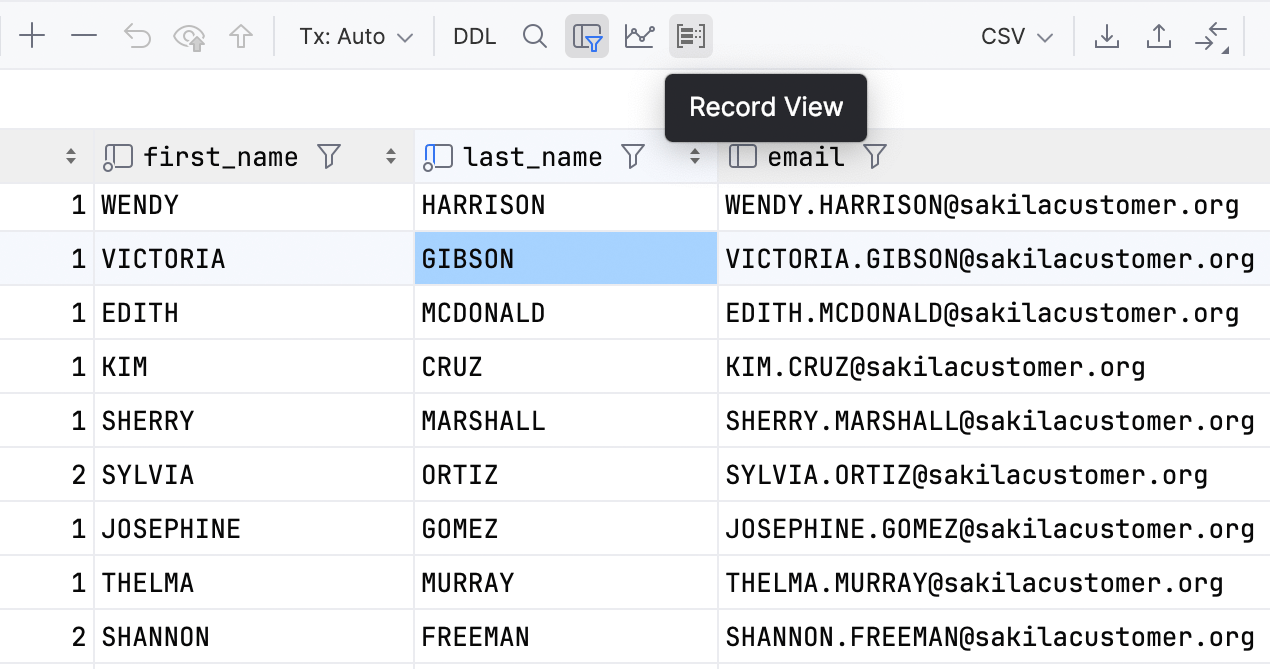
单记录视图
现在,您可以在数据编辑器中关注单个记录。 要打开记录视图,请使用 Ctrl/Cmd+Shift+Enter 快捷键或工具栏上的 Record View(记录视图)按钮  。
。
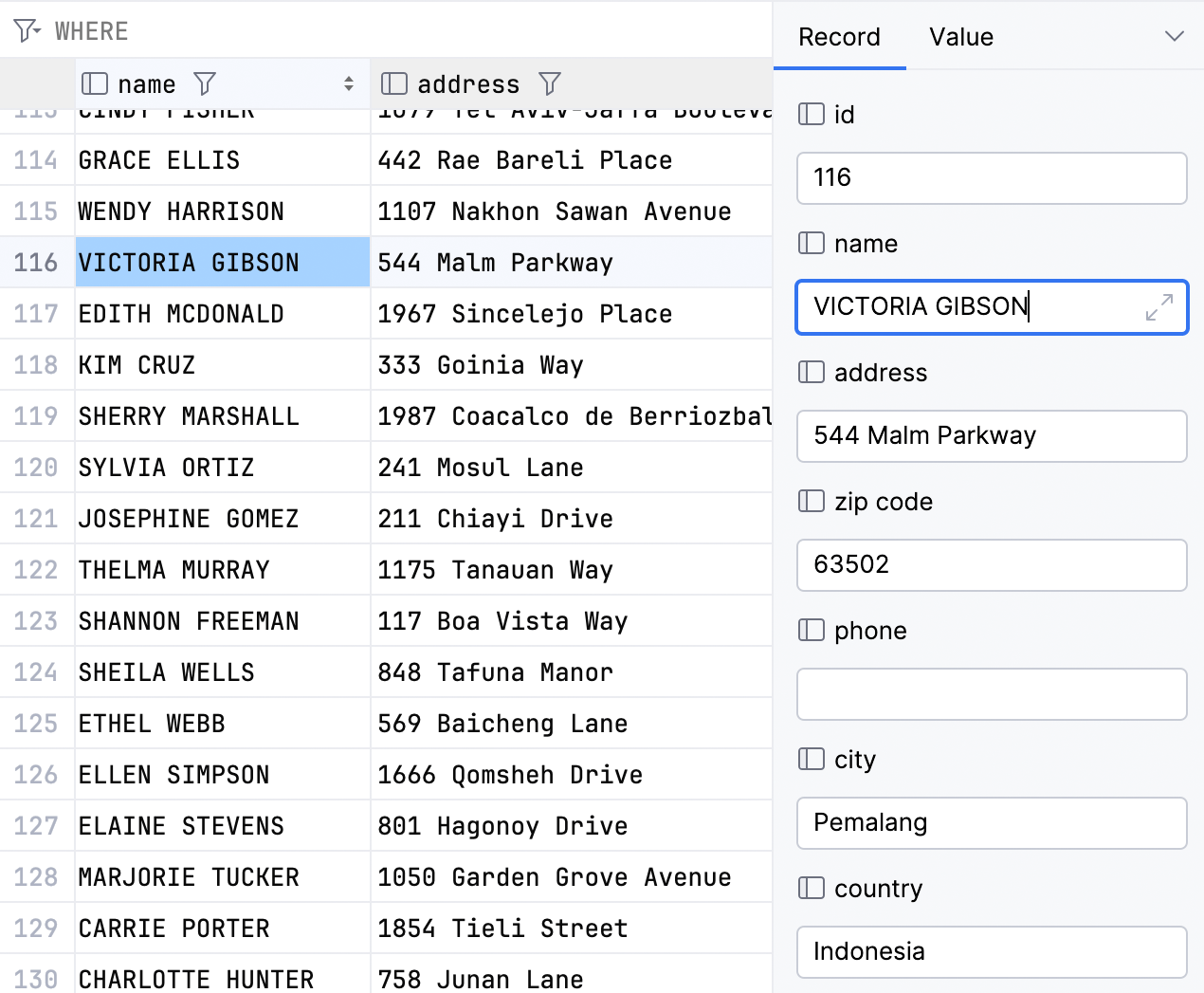
如果记录视图中的单元在主网格中可编辑,则它们也将可编辑。

如果适合您的用例,您还可以将布局更改为两列:
移动 CSV 文件中的列
从 2024.1 开始,您可以在数据编辑器中移动 CSV 文件的列,并且更改将应用到文件本身。
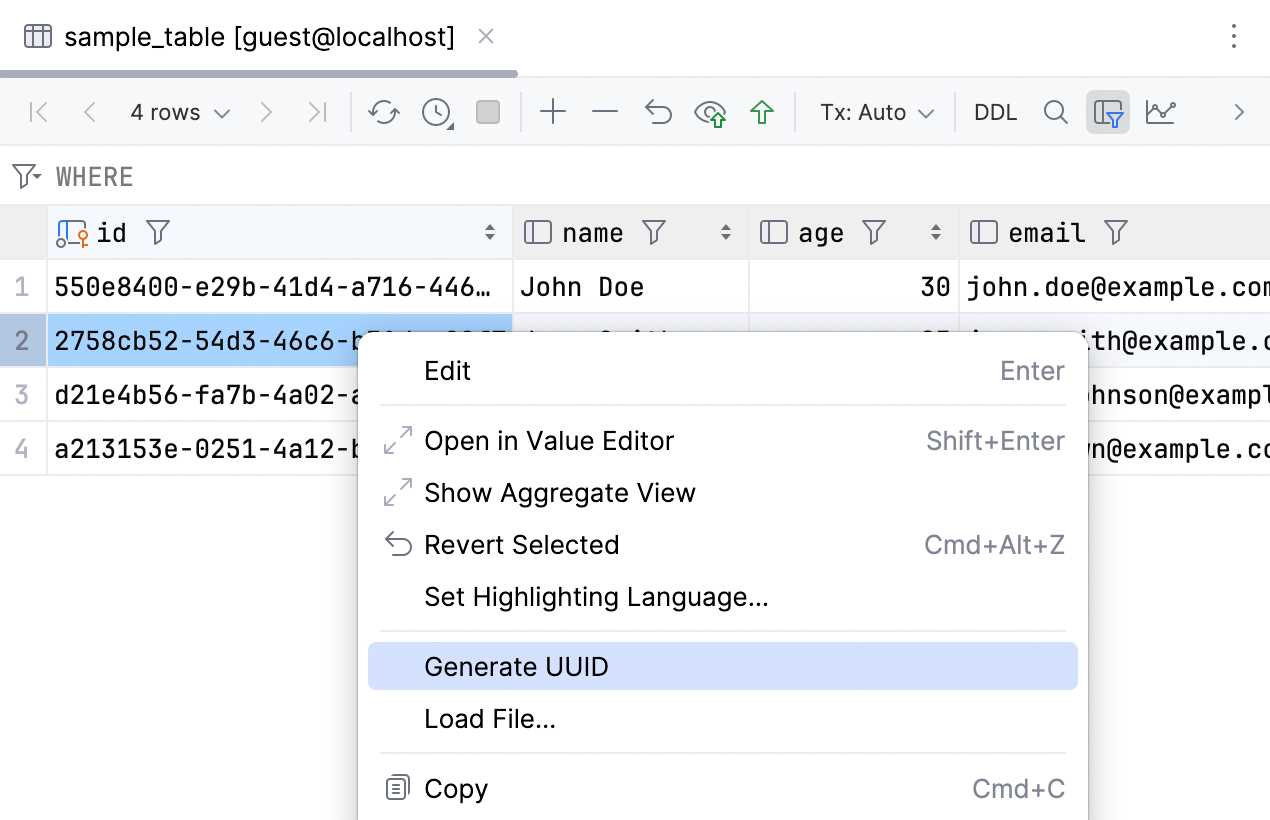
针对 UUID 的更多功能
为了回应我们在问题跟踪器中收到的各种请求,我们简化了 UUID 的使用:
- 我们添加了一个新操作:Generate UUID(生成 UUID)。
- 现在,可以通过 UUID 编辑任何列,包括由
binary(16)、blob(16)和类似类型表示的列。 - 现在,可以在编辑时验证 UUID 列中的值。 PostgreSQL
会话简化
过去几年中,我们收到了大量用户反馈,他们表示不理解会话的概念,并且此功能对 DataGrip 的学习曲线影响重大。 以下是几个示例:
项目优先的独立控制台会话模型过于多余, 这种模型让打开和执行简单的 SQL 文件相当麻烦。 如果我只想打开和执行脚本,我必须先创建一个项目,把文件添加到项目中,然后打开控制台,再打开会话,把文件附加到会话。 实在太麻烦了。
我先前使用的是 SQL Server Management Studio,感觉 DataGrip 的 UI 太复杂了。 在 SSMS 里,基本上只有服务器、查询和结果。 到了 DataGrip,有会话、控制台还有临时文件等,这让工具对于新用户来说不太直观。
UI 有些地方笨拙又难懂。 当我必须选择一个控制台来运行脚本的时候,我并不完全清楚为什么我必须这样做,或者选择的后果是什么。 这不应该是默认行为。
在 DataGrip 中,“会话”是一个技术术语,指的是连接的容器。 换句话说,连接可以在一个会话内建立、停止和重新建立。 对于每个连接,都有一个会话。
会话附加是一种强大的机制,但在大多数情况下,用户只需要为要运行的查询设置上下文(数据源和数据库或架构)。
从版本 2024.1 开始,用户将不再需要手动选择在哪个会话中运行查询,这适用于所有类型的查询。 会话仍然存在,但您不再需要担心它们。 我们来深入了解这一变化如何影响 DataGrip 的主要用例。
附加和切换数据源
要附加文件,您只需选择数据源,而不是会话。 选择数据源后,再选择架构。
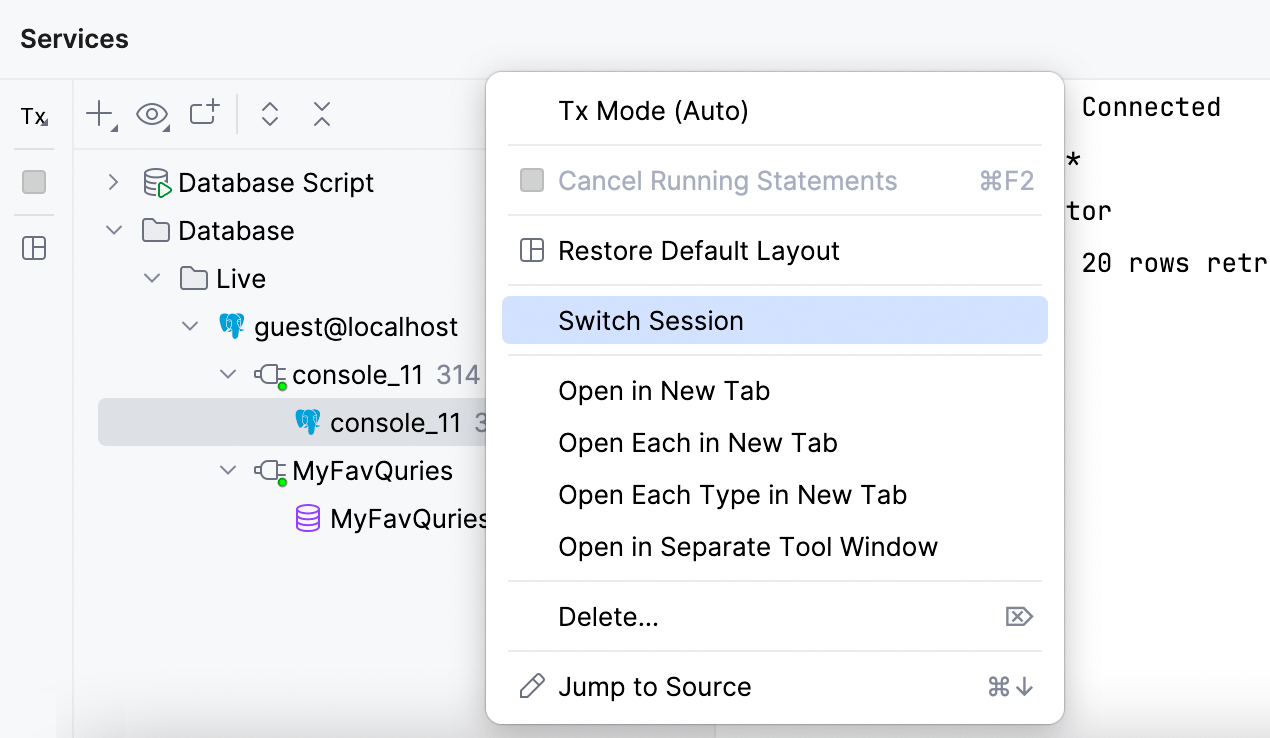
切换会话
Switch Session(切换会话)操作现在仅在 Services(服务)工具窗口的客户端上下文菜单中显示。 它允许您仅在当前数据源内切换会话。
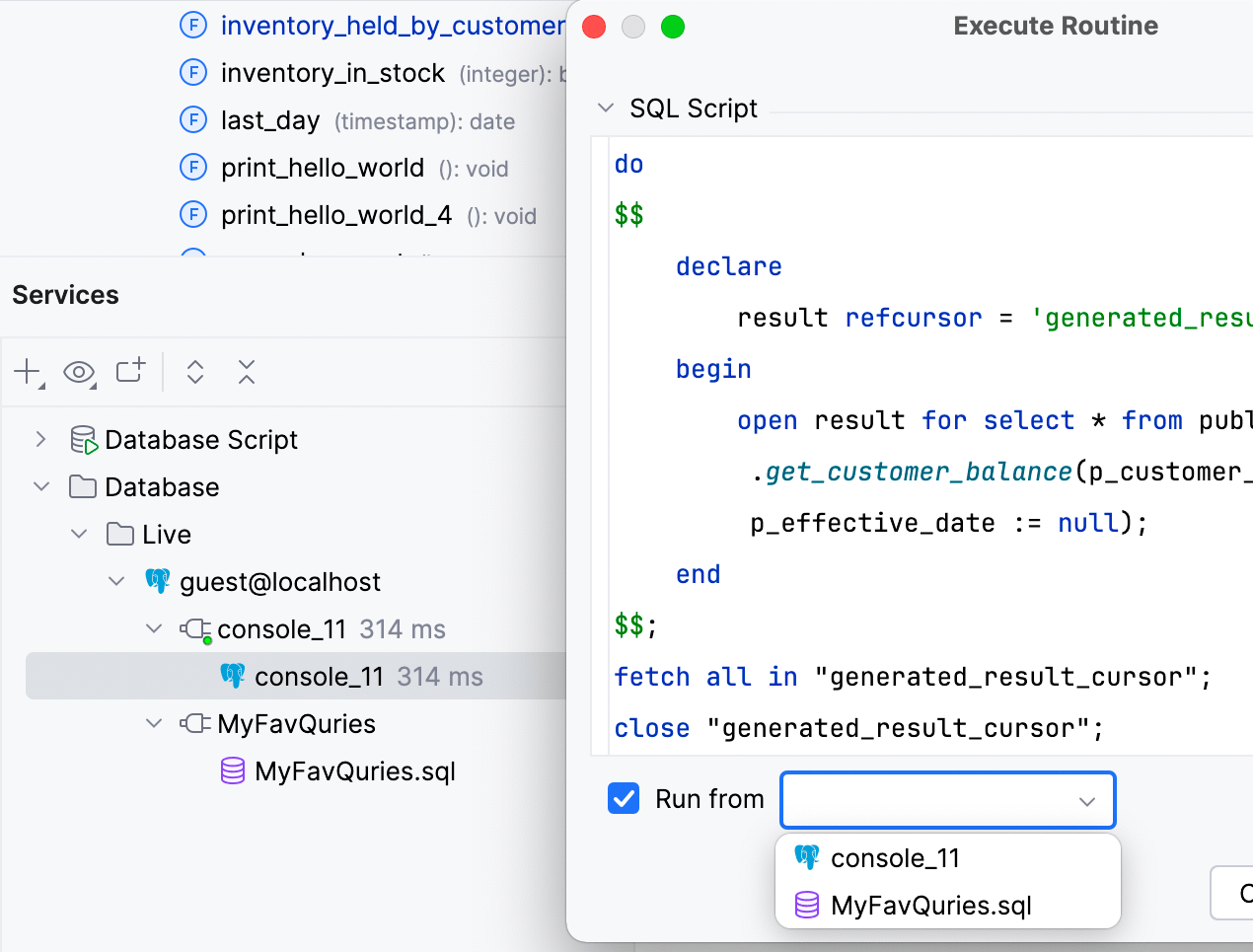
运行函数
您不再需要在启动函数之前选择会话。 在 Execute Routine(执行例程)窗口中,Run from(运行自)选项允许您选择从中启动函数的控制台或文件。
处理代码
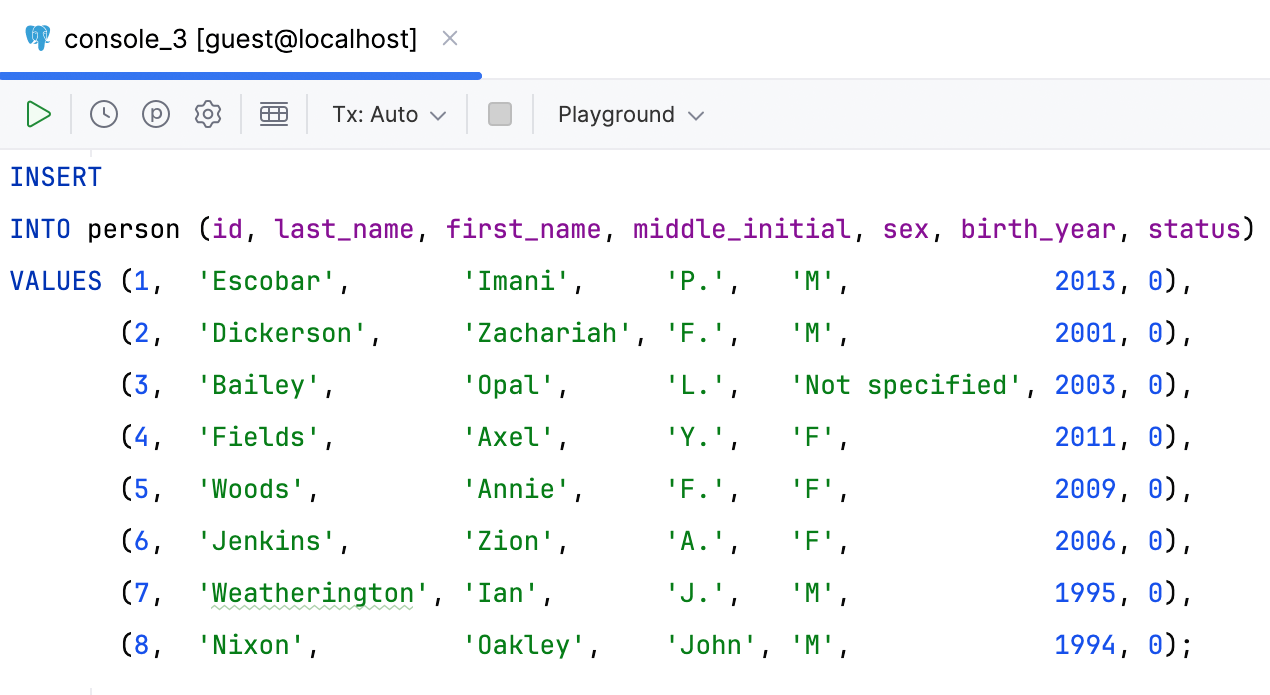
多行 INSERT 语句的对齐代码样式
您现在可以设置多行 INSERT 语句的格式,使其值对齐。 格式化程序将分析每列中值的宽度并应用最合适的宽度。
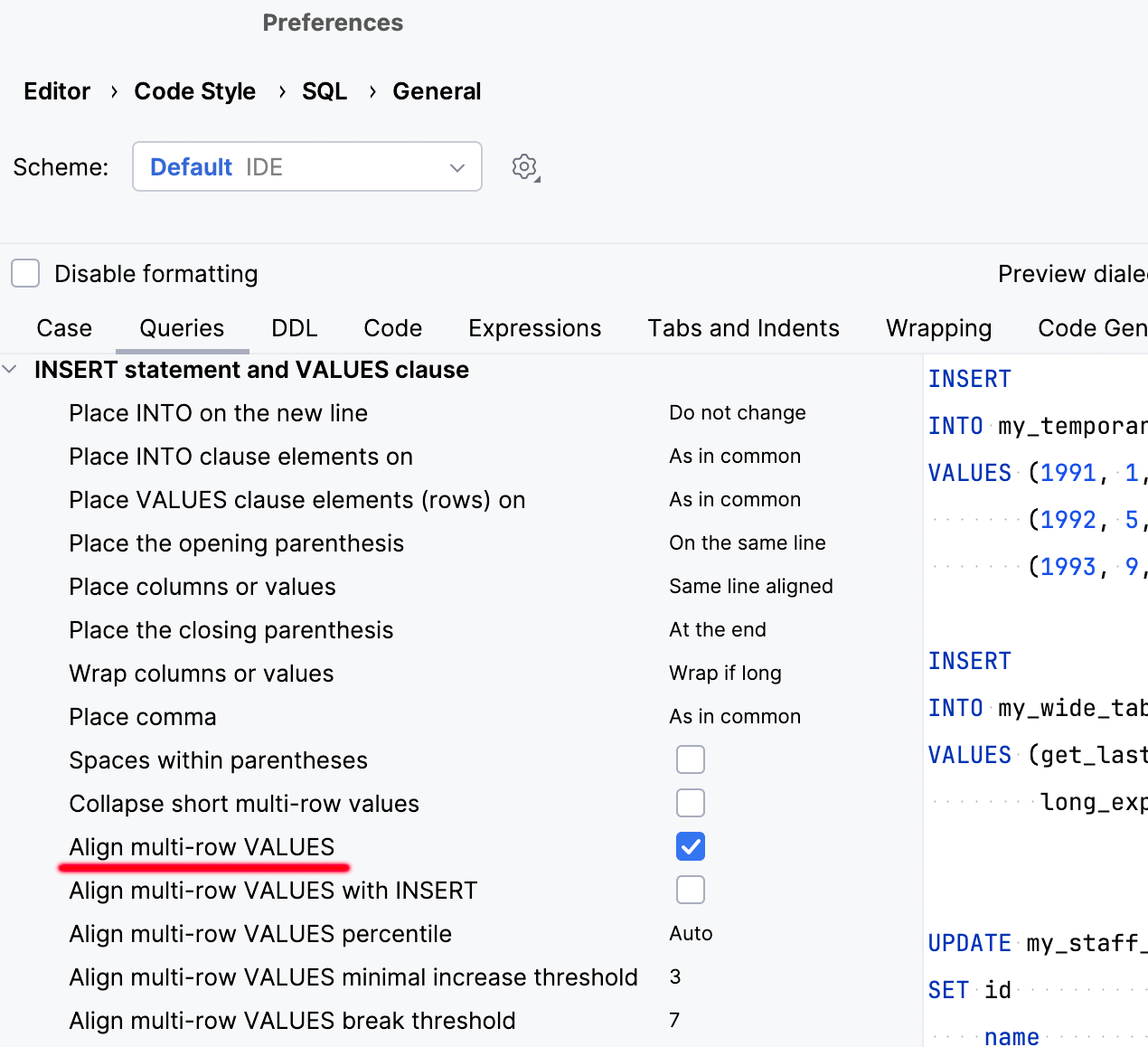
要打开此功能,请启用 Align multi-row VALUES(对齐多行值)选项:
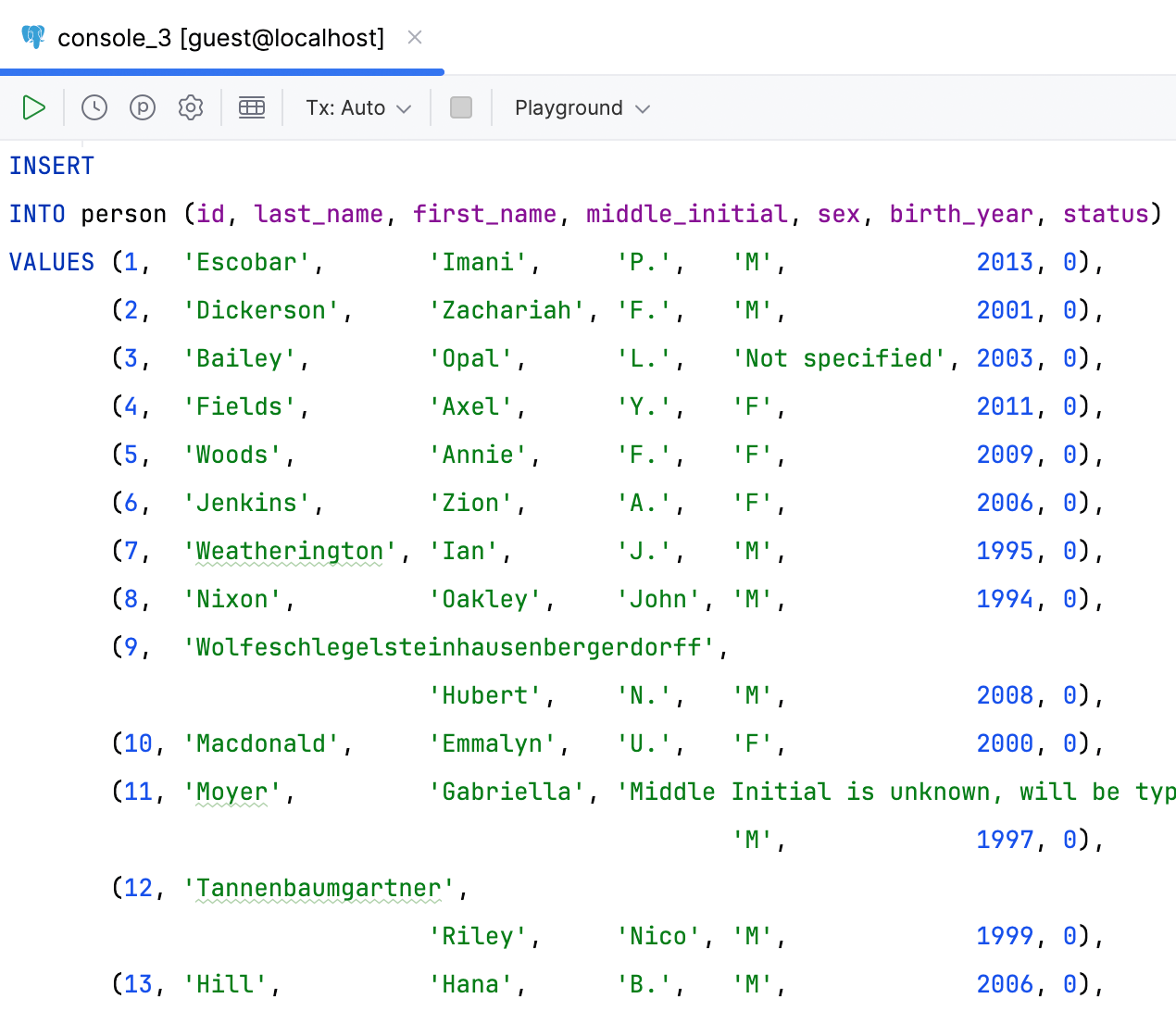
DataGrip 甚至能够处理某些值比其他值长得多的情况。 格式化程序将检测此类值并对其进行例外处理,将剩余字段移动到下一行。
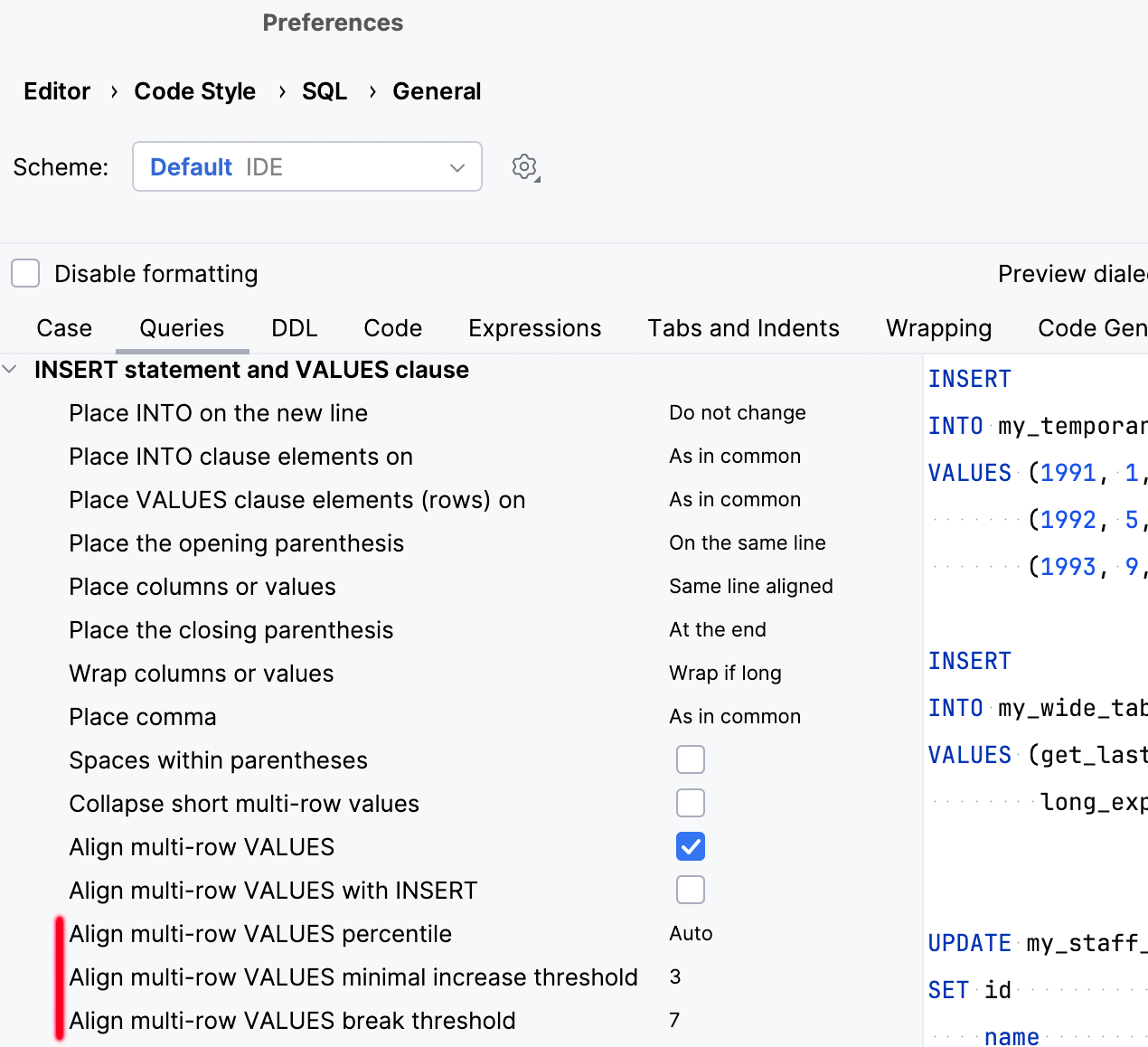
此行为由以下三个选项管理:
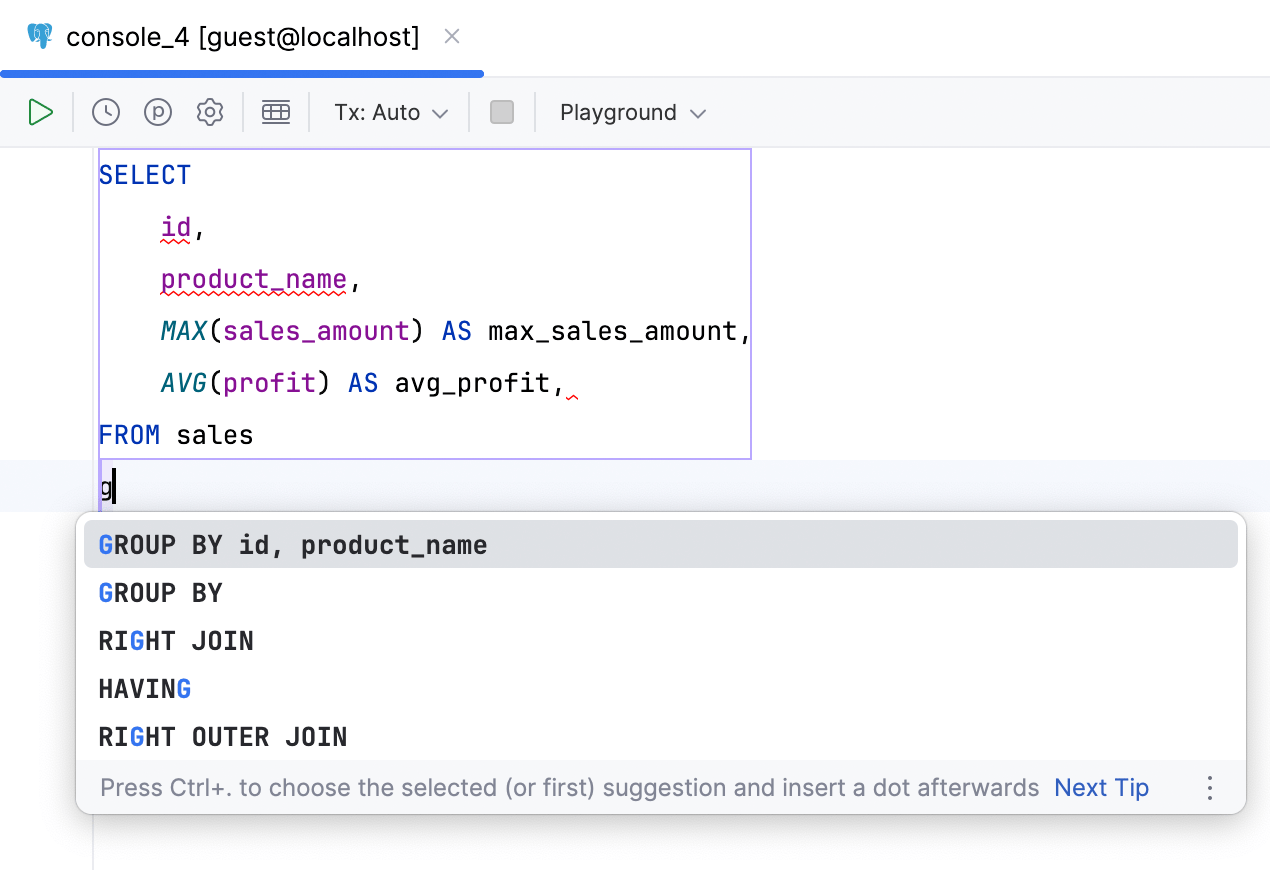
针对 GROUP BY 子句的列补全
DataGrip 现在可以分析 SELECT 子句中使用的聚合,并在 GROUP BY 子句建议中包含适当的列列表。
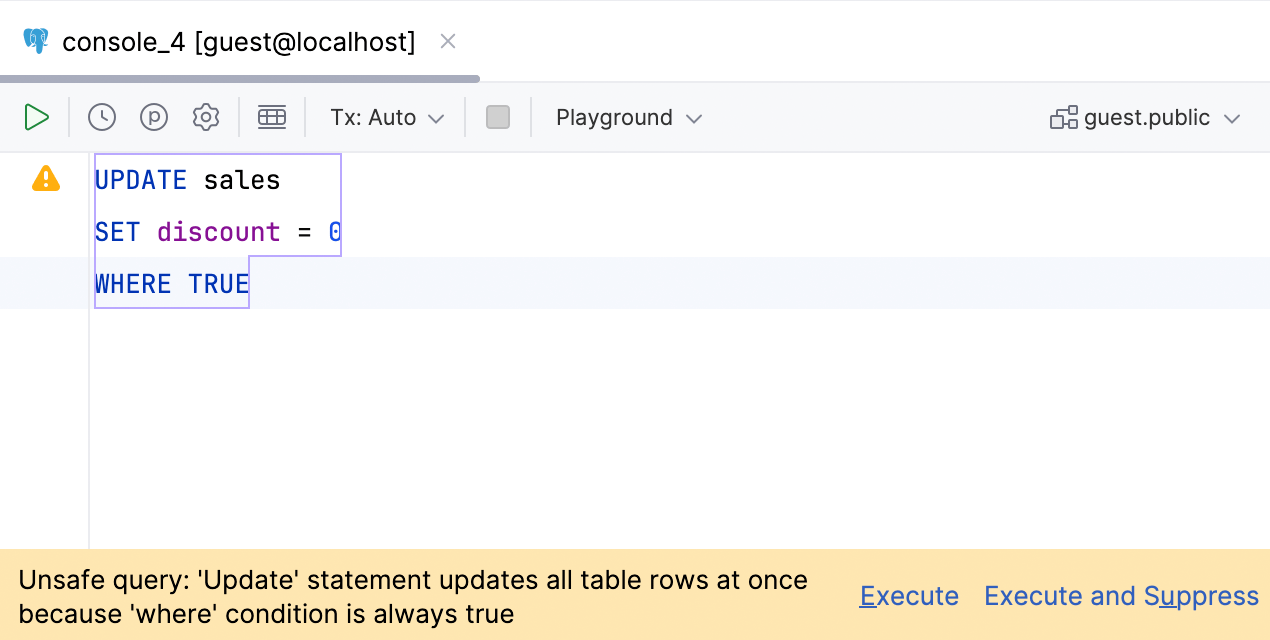
针对 WHERE TRUE 子句的警告
我们扩大了 Unsafe query(不安全的查询)警告。 现在,如果您使用 WHERE TRUE 条件或其变体之一运行查询,它会向您发出警告。 如果您喜欢使用此子句进行调试,但偶尔会忘记更改,这可能非常实用!

用于接受建议的自定义符号
我们添加了指定您将使用哪些符号接受代码补全建议的功能,使您可以更快编写 SQL。 为此,您需要启用两个选项。 第一个选项:
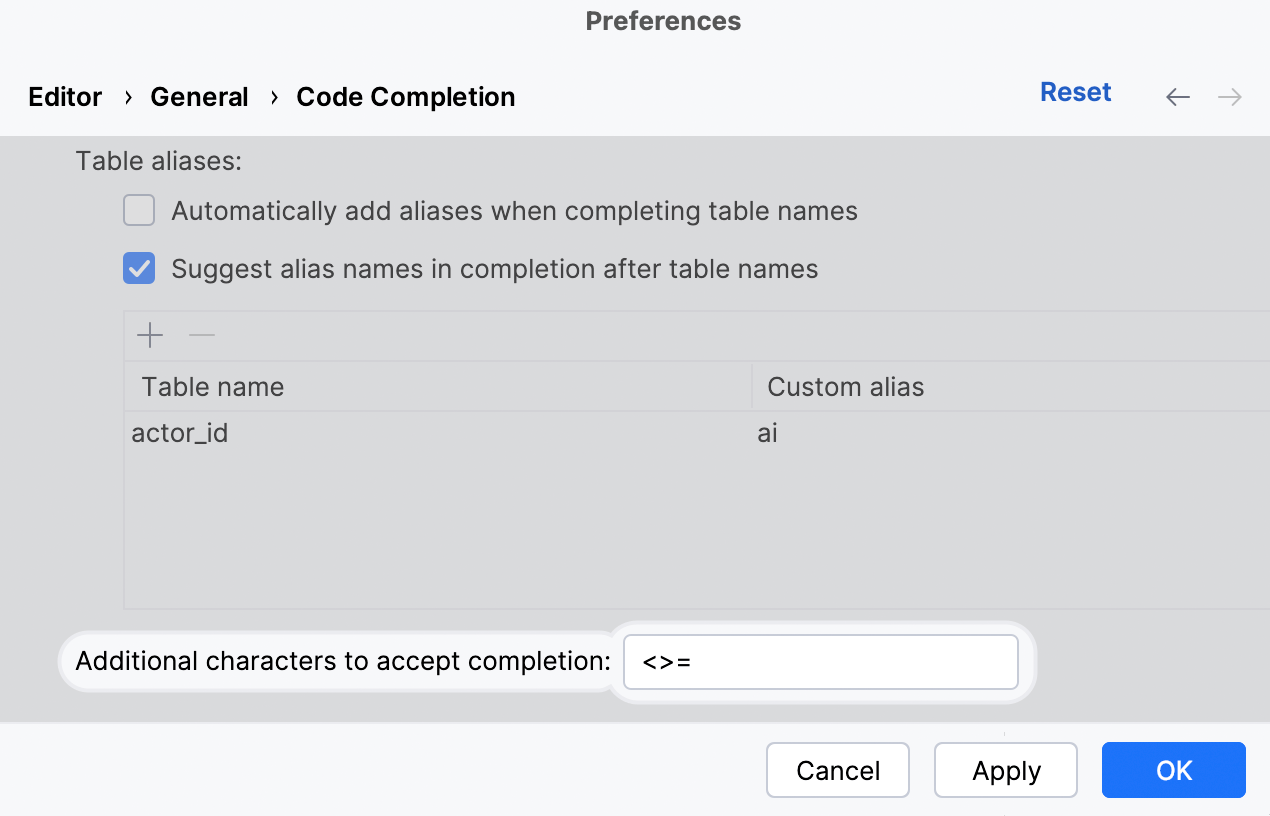
第二个选项:
使用运算符时,此功能特别实用:
编辑器中的粘性行
为了简化大文件的处理,我们在编辑器中引入了粘性行。 滚动时,此功能会将 CREATE 语句等关键结构元素固定到编辑器顶部。 这将使上下文始终保持在视野中,您可以点击固定的行快速浏览代码。
此功能默认启用。 您可以通过 Settings/Preferences | Editor | General | Appearance(设置/偏好设置 | 编辑器 | 常规 | 外观)中的复选框将其关闭,您还可以在其中设置固定行的最大数量。
其他
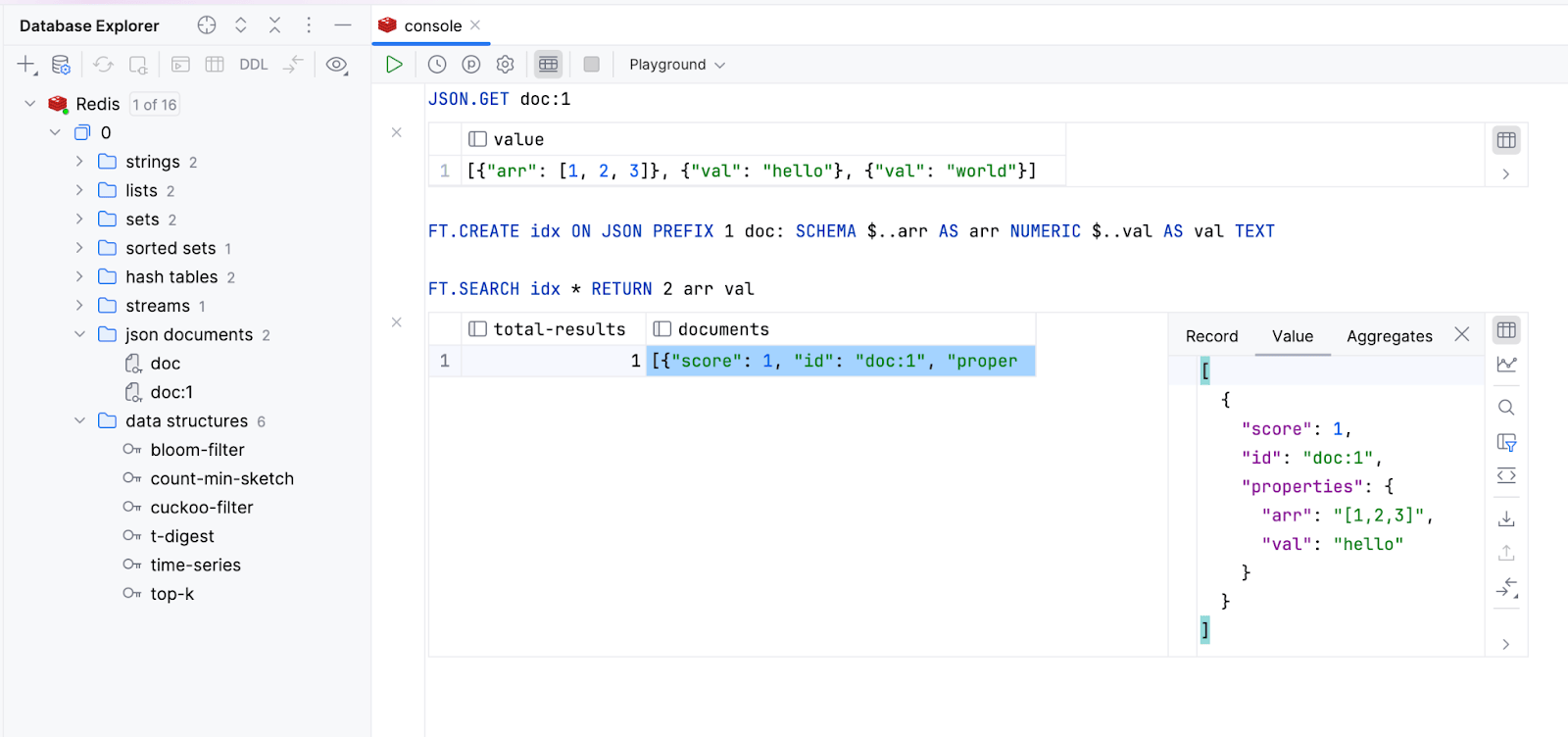
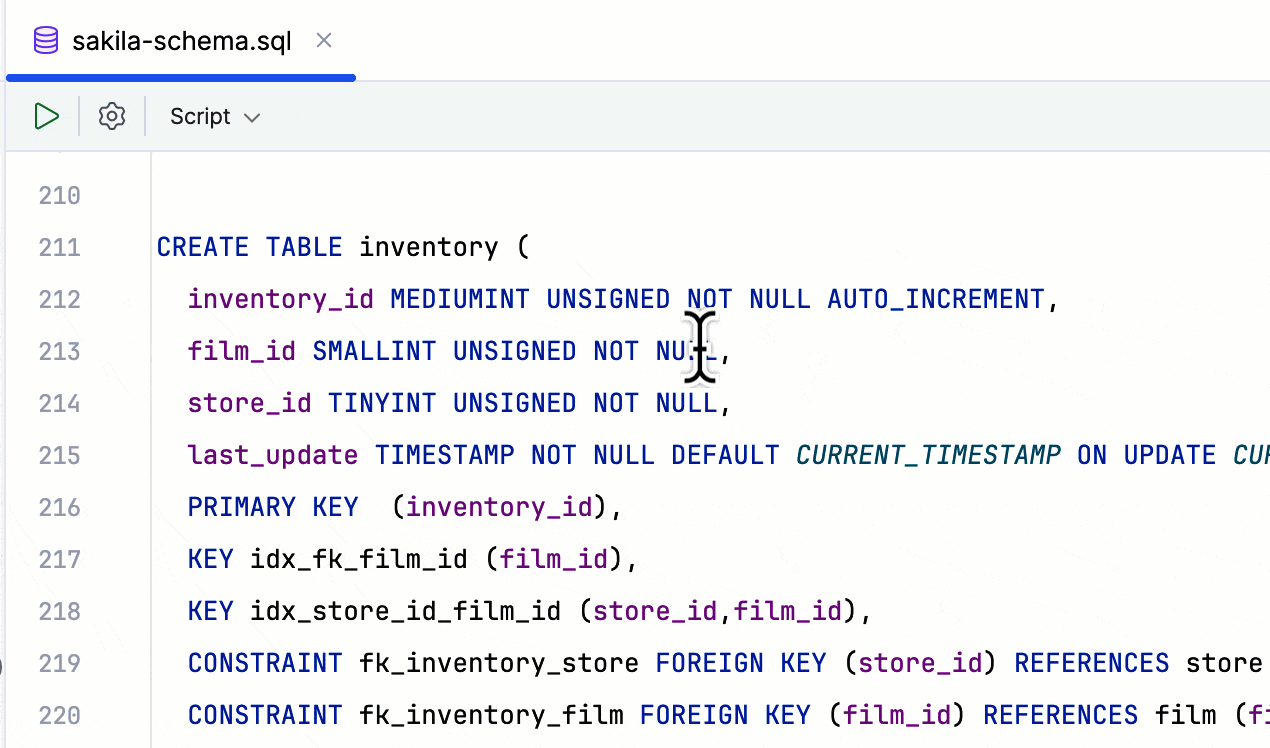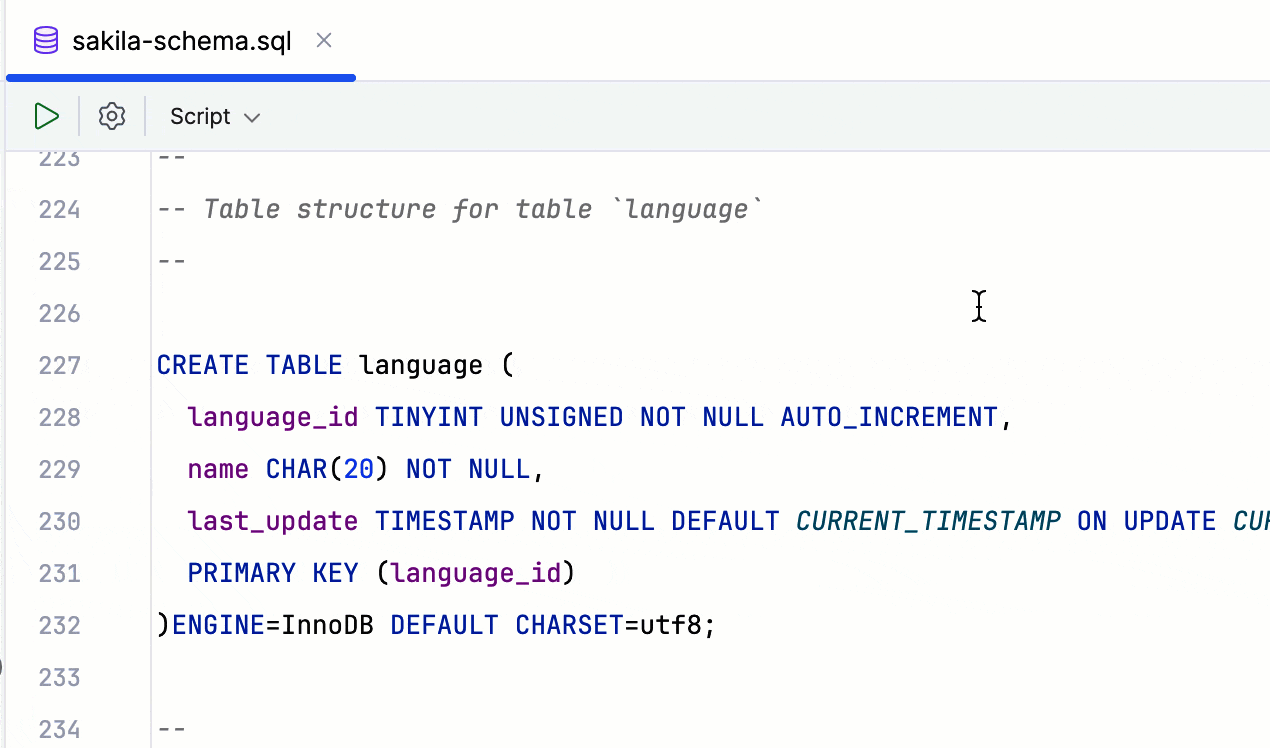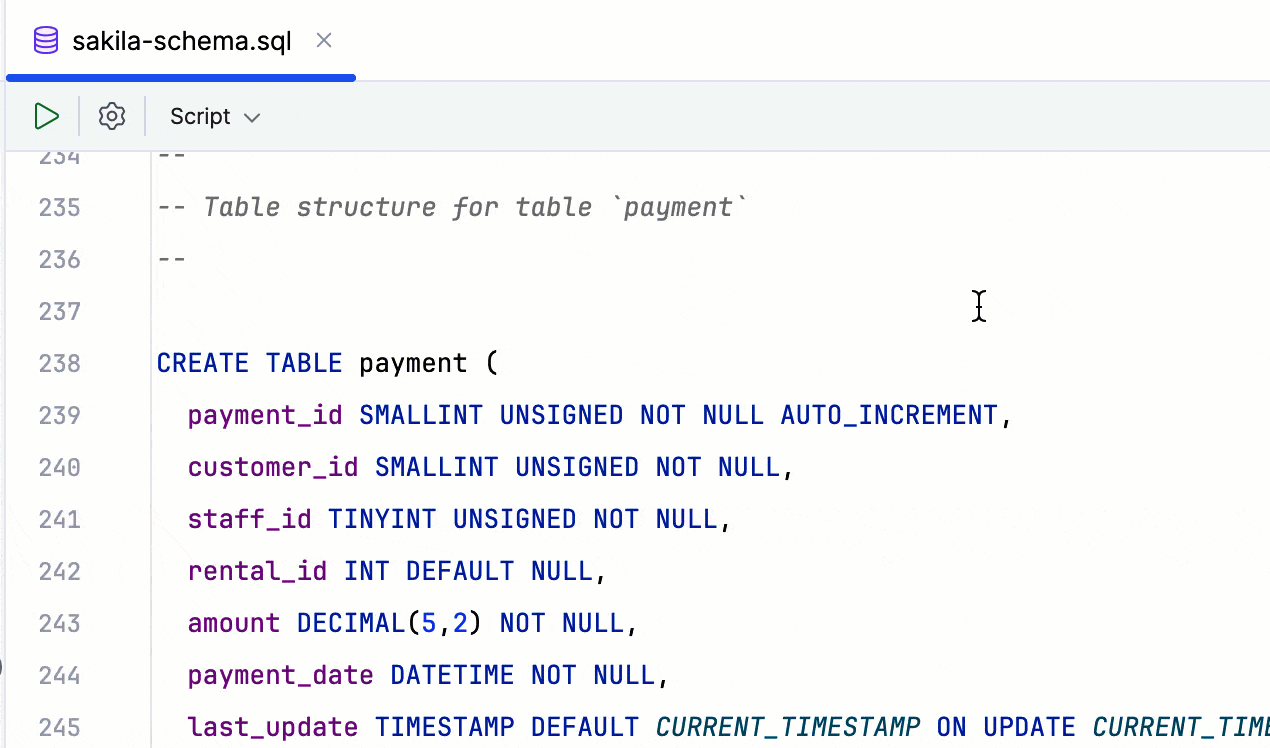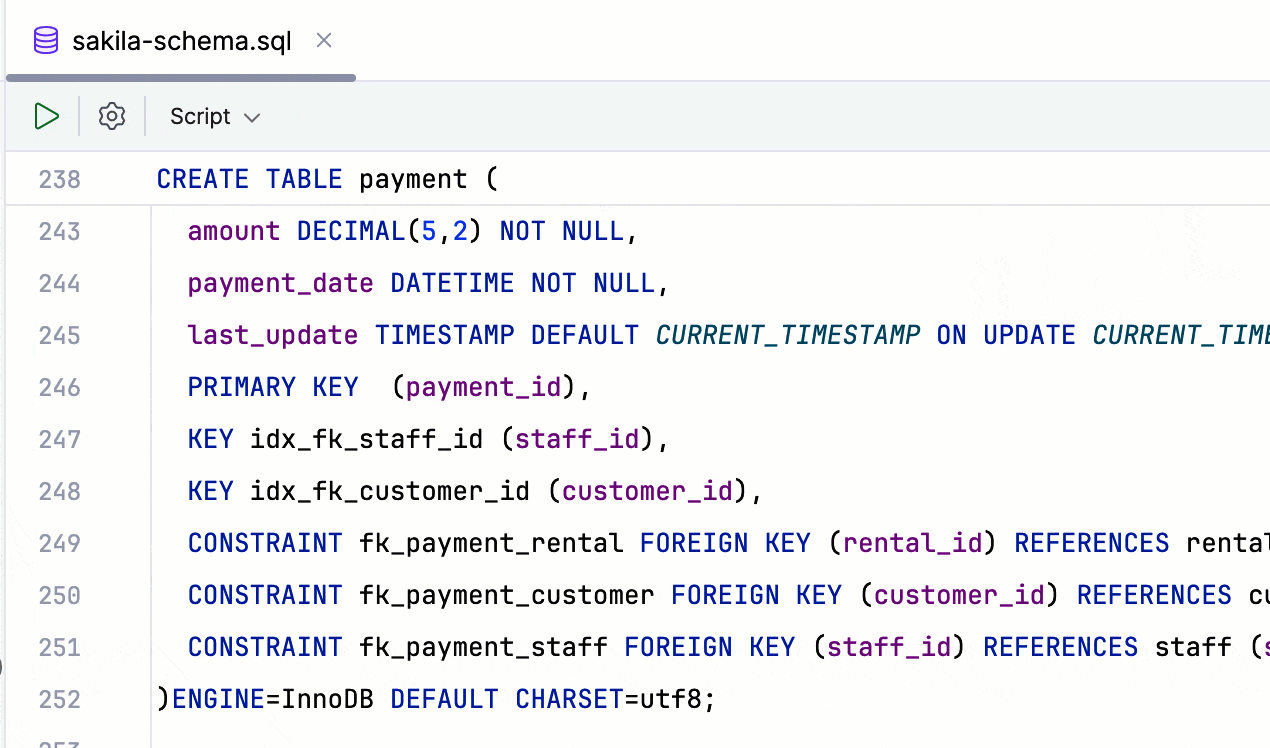
对 Redis Stack 模块命令的支持 Redis
DataGrip 现在支持来自四个主要 Redis Stack 模块的命令:RedisJSON、RediSearch、RedisBloom 和 RedisTimeSeries。 此支持还要求 v1.5 的驱动程序。 RedisGraph 模块已过时,将不再受支持。 借助此模块支持:
- 您可以从这些模块发送命令并查看结果。
- 来自这些模块的命令会被正确高亮显示。
- 这些模块提供的类型的键显示在数据库浏览器中。
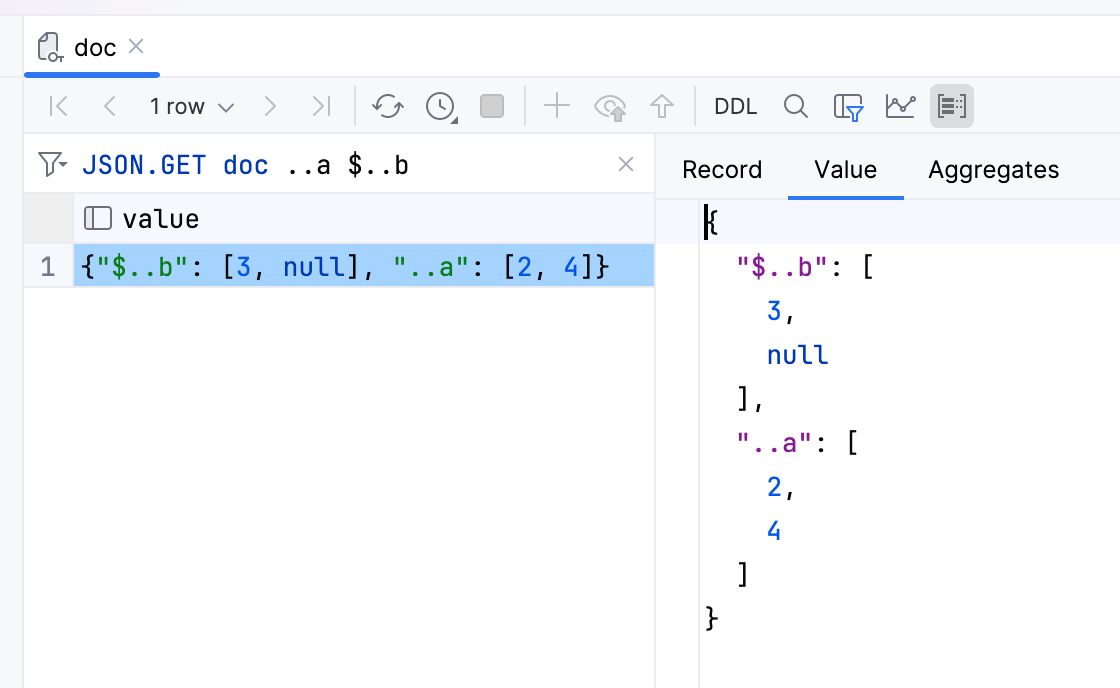
JSON 文档
JSON 文档现在显示在专属文件夹中。 您可以在数据查看器中查看其值,并且可以指定 JSON 路径。

其他数据类型
RedisTimeSeries 和 RedisBloom 模块提供的类型的键显示在 data structures 文件夹下。
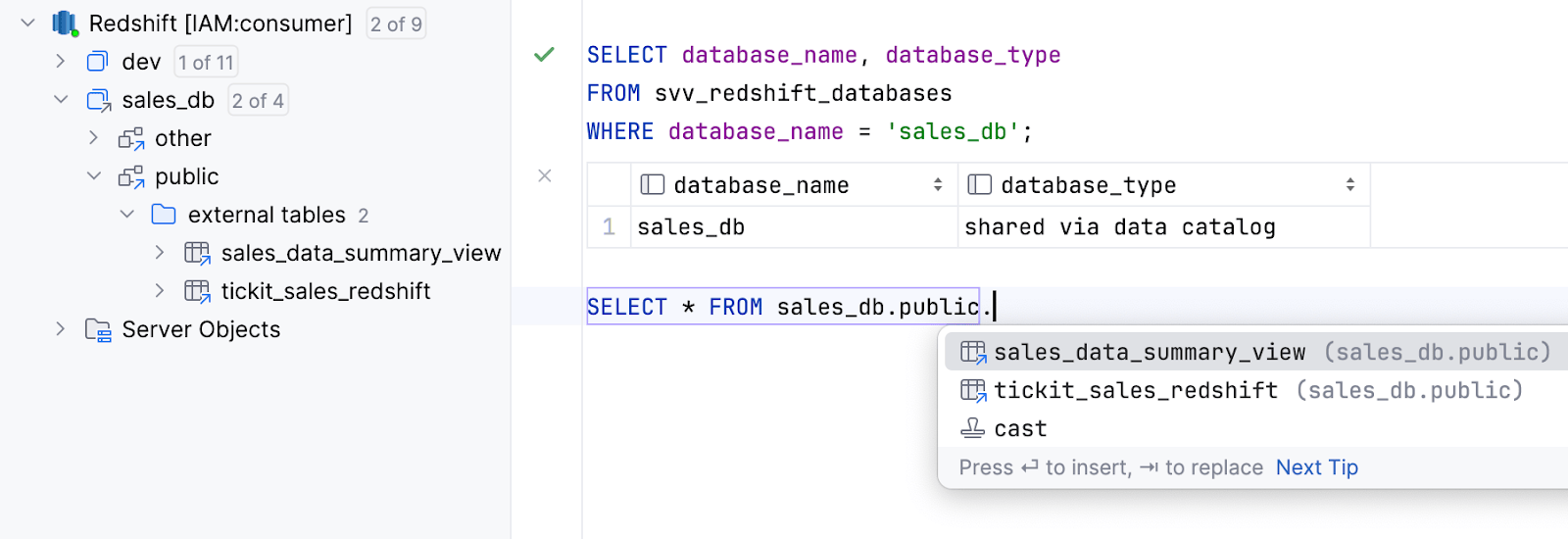
对通过数据目录共享的外部数据库的支持 Amazon Redshift
通过数据目录共享的外部数据库现已得到支持, 其内容可以内省和补全。