DataGrip 2022.2 最新变化
DataGrip 2022.2 现已发布! 这是 2022 年的第二次重大更新,其中包含各种增强功能。 让我们看看都有些什么!
导入多个 CSV 文件的选项
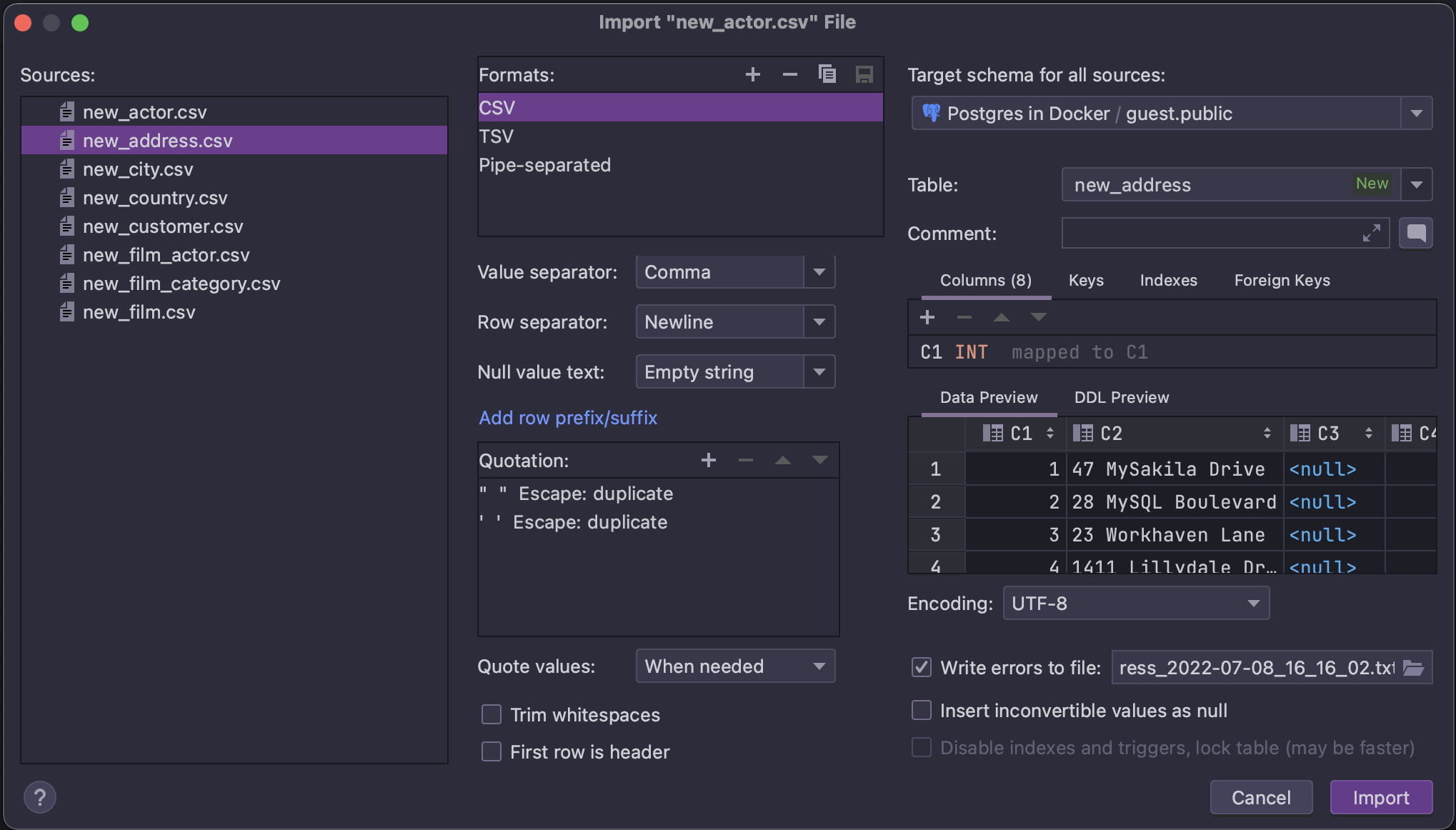
我们实现了选择多个 CSV 文件并将其一次导入的功能,以此增强文件导入过程。
Playground(演练场)和 Script(脚本)解析模式
DataGrip 需要了解对象的含义才能解析 SQL 脚本中的数据库对象。 只有这样,IDE 才可以提供正确的代码补全并将对象的用法视为链接。
通常,解析上下文应该与运行上下文匹配,但这对于 DataGrip 来说并不容易。 因此,直到最近还有多个解析相关问题。 以下是可能出现的情况:
- 所有对象均已解析,但脚本无法在数据库中运行。
- 当 Auto-qualify(自动限定)选项打开时,如果对象位于默认数据库或架构中,它们有时会保持非限定状态。
- 如果在不同的数据库或架构中有多个同名对象,现有列将无法解析,甚至 Expand column list(展开列列表)操作有时也会生成错误的列表。 同时,也有解析不存在的列的风险。
这些问题的原因是,对于每个控制台或本地文件,DataGrip 都将其对象解析为右上角下拉菜单中选择的上下文和默认数据库或架构(或 SQL Resolution scopes(SQL 解析范围)设置中的条目)。
处理包含切换上下文的 USE 或 SET SEARCH PATH 语句的脚本时这没问题。 但是,IDE 也需要知道文件开头解析到哪里。 因此,它将默认数据库或架构(或 SQL Resolution scopes(SQL 解析范围)设置中的条目)视为文件开头最合适的上下文。
也就是说,如果文件中没有 USE 或 SET SEARCH PATH 语句,则 DataGrip 不应试图将文件的开头解析为上下文之外的位置。 为了应对这种情况,我们引入了 Playground(演练场)和 Script(脚本)这两种解析模式,让 DataGrip 知道要遵循哪种方式。
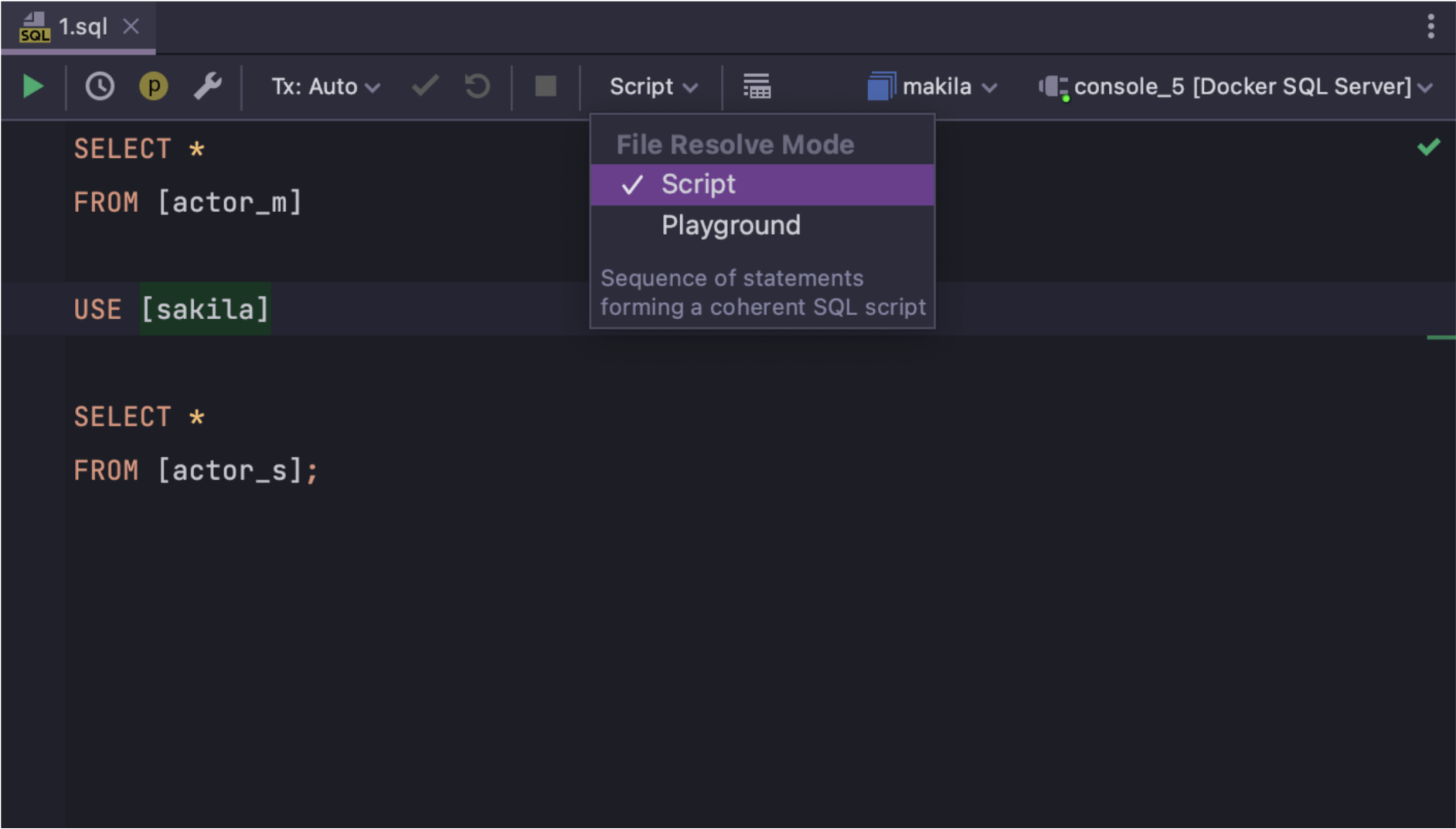
在 Playground(演练场)模式下,DataGrip 将所有对象解析为上下文,即架构选择器、解析范围或默认数据库中的值。 如果文件只是一组未连接的查询,彼此独立且没有特定顺序,则效果最佳。 Playground(演练场)模式现在是查询控制台的默认设置。
在 Script(脚本)模式下,文件的开头被解析为上下文,但脚本中的所有 USE 语句都会更改解析的上下文,因为它们是脚本顺序逻辑的一部分。 这适合查询具有顺序逻辑且应该作为单个脚本运行的情况。 Script(脚本)模式现在是本地文件的默认设置。
在模式之间切换很容易。 使用工具栏上的下拉菜单即可,如屏幕截图所示。
代码生成
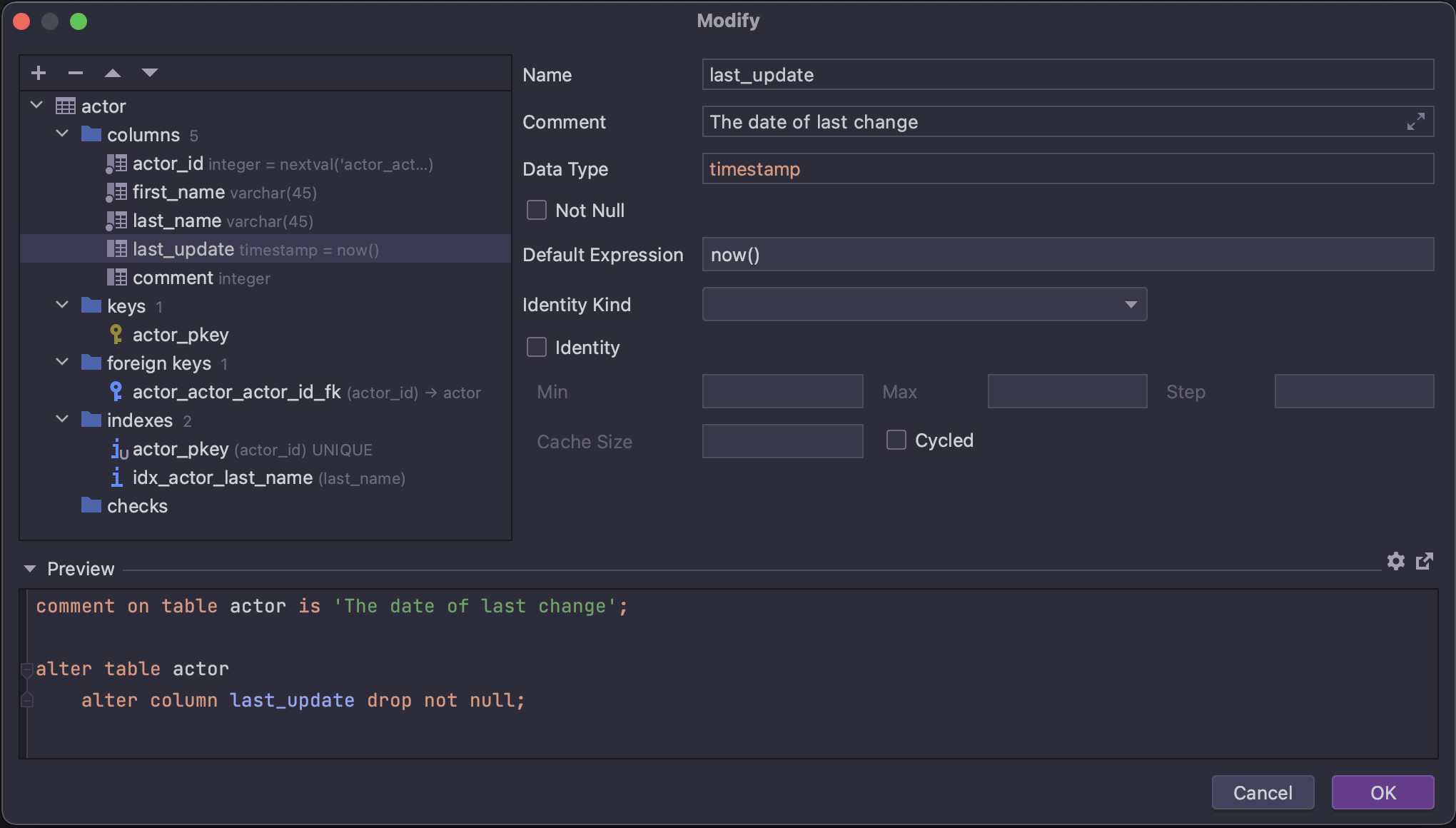
新的 Modify(修改)UI
新的 Modify(修改)UI(其基本版本在 2022.1 版本中引入)现已成为默认选项。 从 DataGrip 2022.2 开始,可以使用新 UI 添加和编辑表的所有子对象。
在此发布周期内,上下文菜单将继续提供旧 UI。
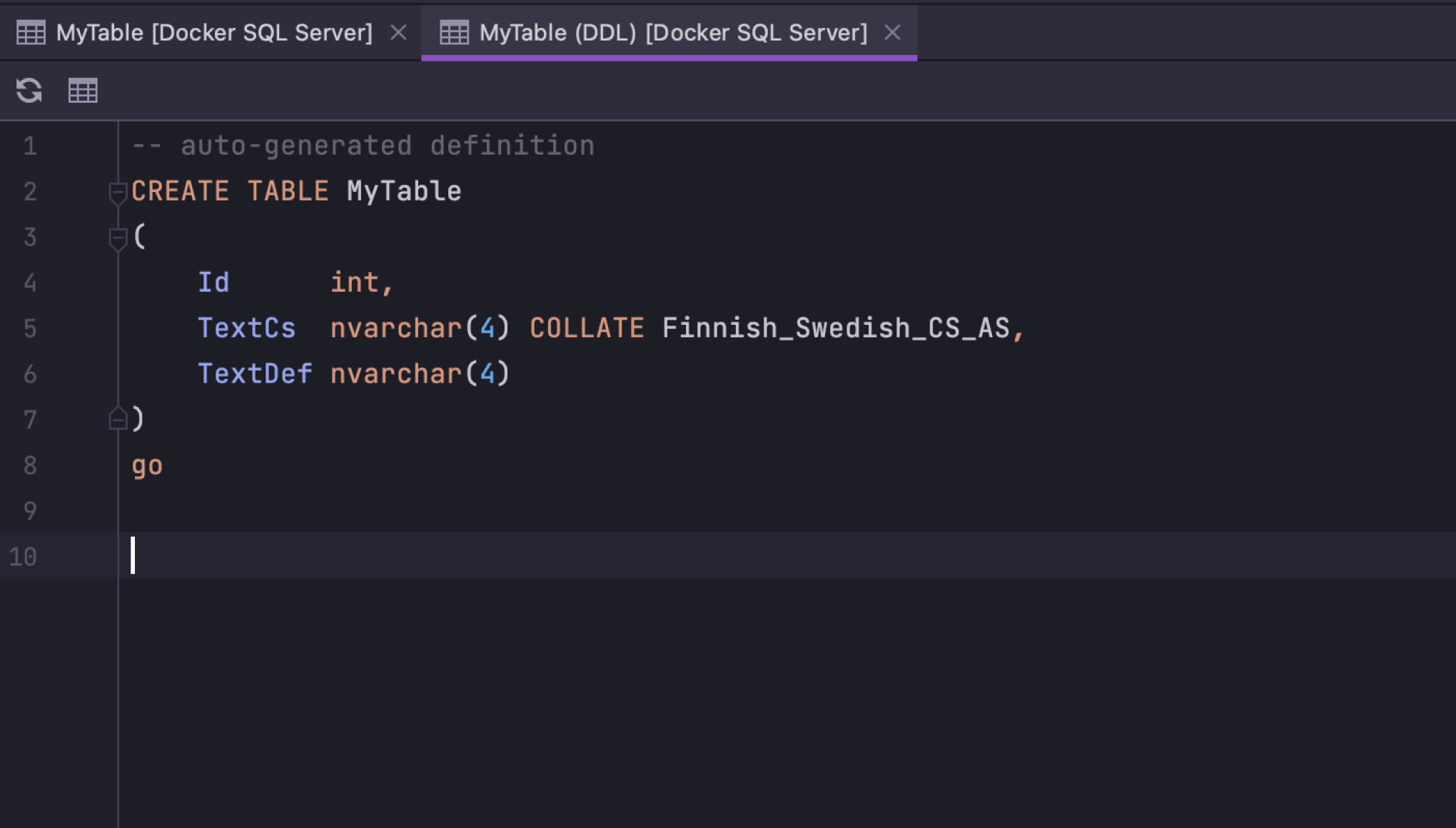
对排序规则和字符集的支持 SQL Server
排序规则和字符集现在通过表的 DDL 生成。
按键映射中的类别
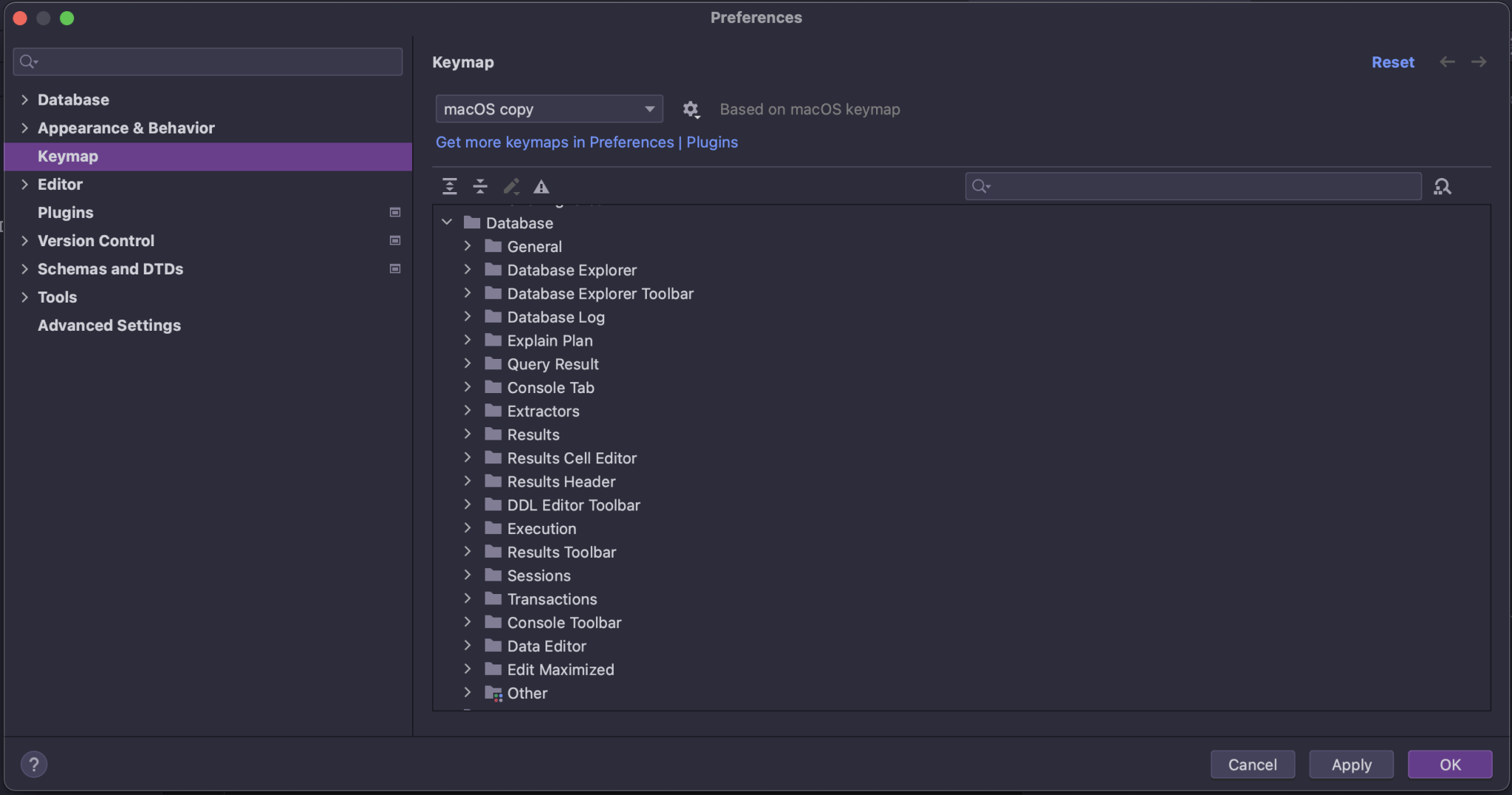
此前,所有数据库功能相关操作都存储在按键映射的四个不同位置。 这种几乎没有逻辑的结构是 IDE 的历史遗留问题。
为了帮助您查看所有可用操作,我们重新安排了结构并将所有操作置于数据库上级组之下的组中。
DDL 数据源中的范围
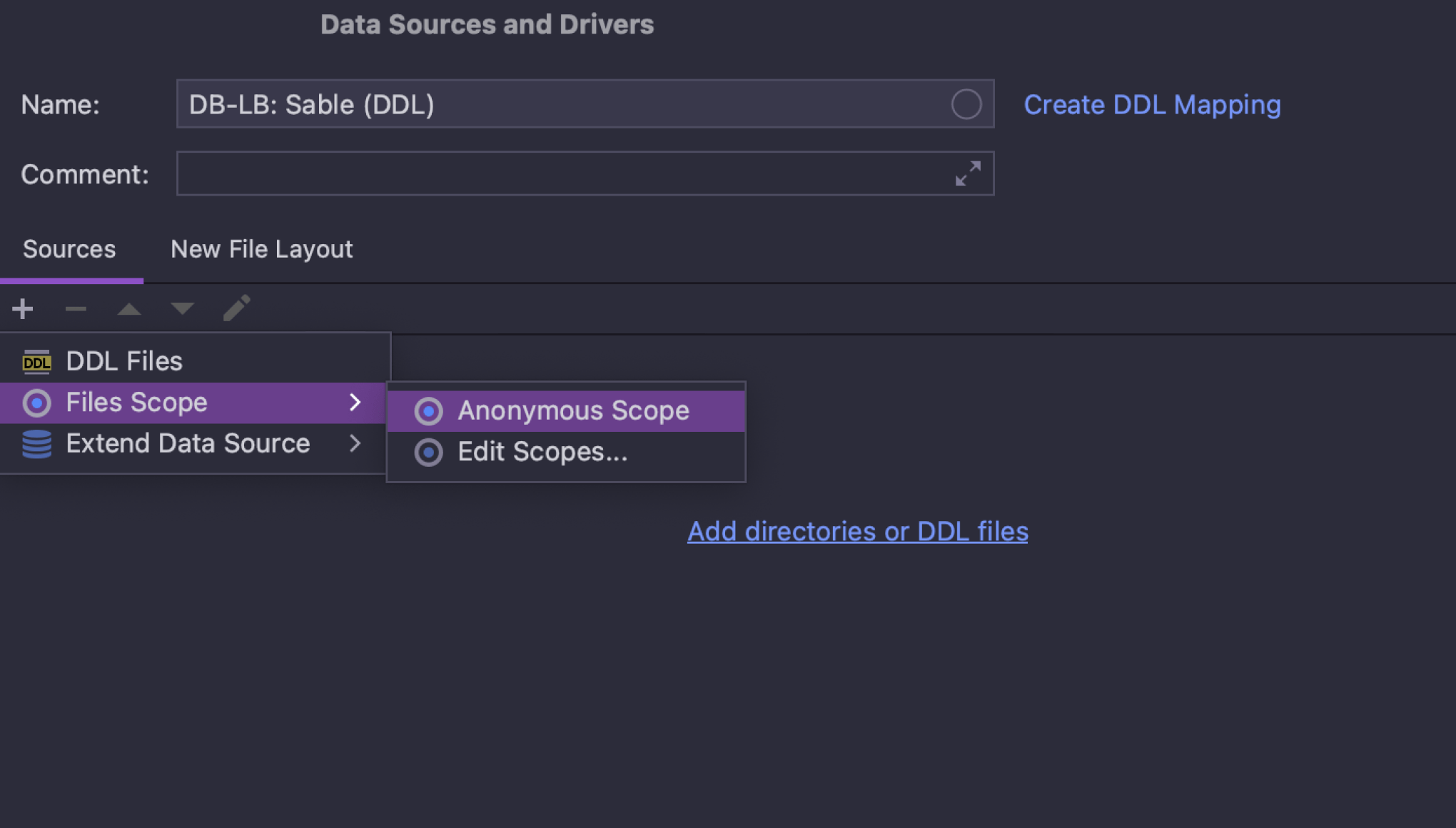
您现在可以将文件范围设置为 DDL 数据源的源。 这让您可以轻松筛选 DDL 数据源的文件夹。 例如,您可以排除子文件夹。
其他
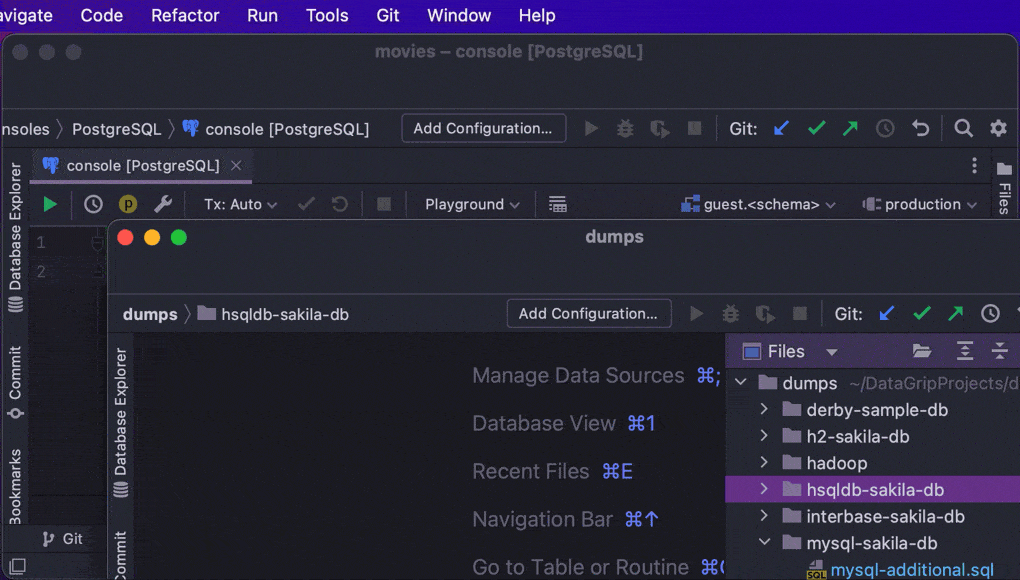
macOS 上的 Merge All Project Windows(合并所有项目窗口)操作
我们为 macOS 用户引入了一项功能,利用此功能可以将所有打开的项目窗口合并成一个,将其变成标签页。 此操作位于 Window(窗口)菜单中。
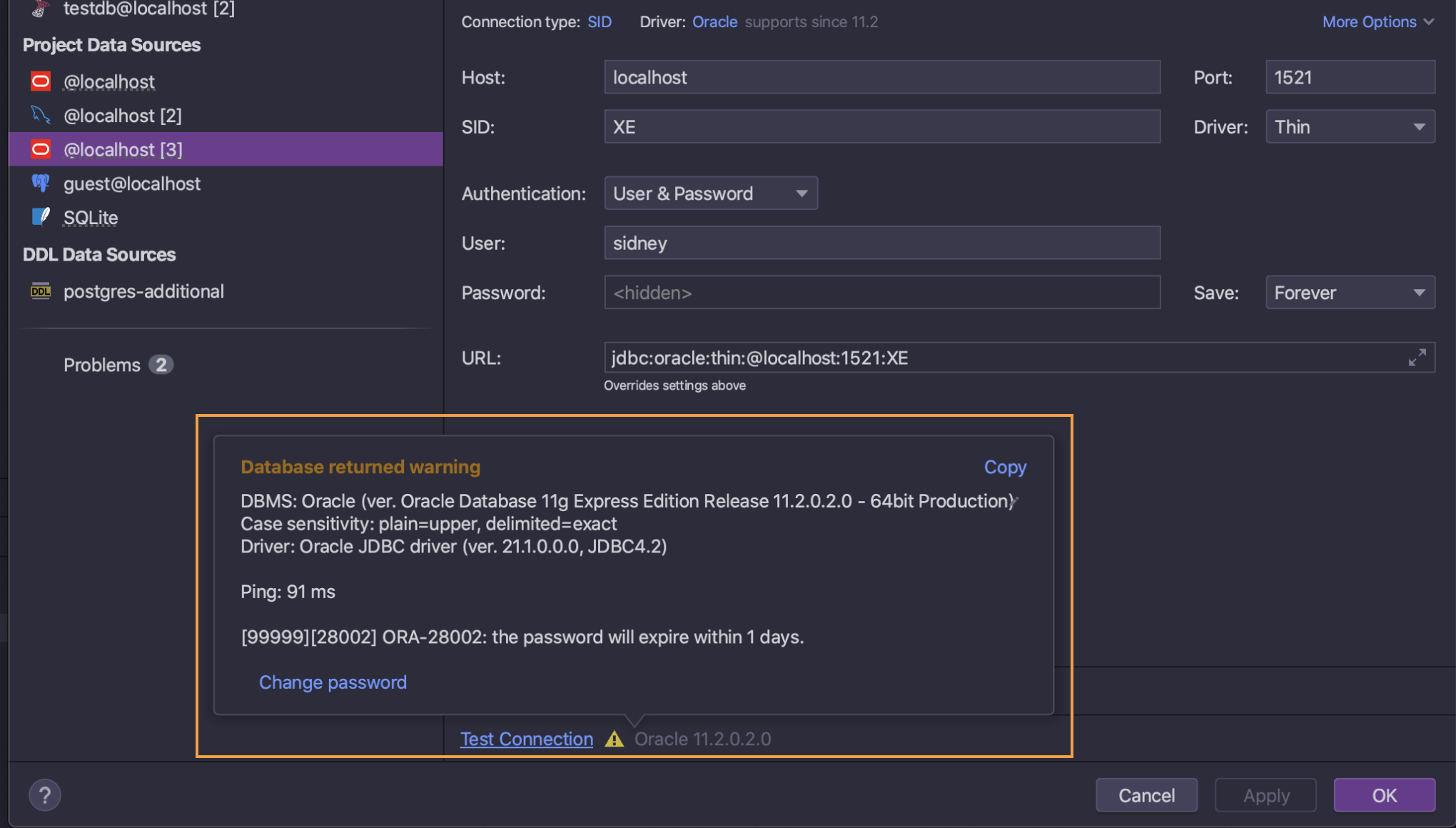
密码过期警告 Oracle、Vertica
当密码即将过期时,Oracle 和 Vertica 数据库可以提供警告。 DataGrip 现在会检索此信息并在 Test Connection(测试连接)激活后显示信息。
对 DuckDB、Mimer SQL 和 Apache Ignite 的基本支持
我们向基本支持列表添加了 3 个新数据库:DuckDB、Mimer SQL 和 Apache Ignite。
数据编辑器
质量改进
- DBE-10971:表顺序现在保存在数据编辑器中。
- DBE-7888:日期选择器中的 2 月回来了!
- DBE-15454:具有混合内容类型的二进制列现在可编辑。
- DBE-7804:如果最后一个值为空且没有新行,CSV 导入不会再在最后一行失败。
- DBE-15335:SQL-Insert-Multirow 提取器将生成正确的查询。
- DBE-14980:打开单元的 Quick Documentation(快速文档)时,将自动加载相关数据。
- DBE-15639:已修正 DDL diff(DDL 差异)预览的 Migration(迁移)窗口中 Origin(原始)和 Target(目标)对象的错误放置。
- DBE-15694:现已支持运算符族匹配。
- DBE-15644:转储到 DDL 数据源时,PostgreSQL 现在遵循 Fire 模式。
- DBE-8557:Azure SQL Database
SET ROWCOUNT在 Azure 查询之前执行以限制页面大小。
查询控制台
质量改进
- DBE-996:搜索栏不再隐藏工具栏。
- DBE-11616:ClickHouse 对
ALTER TABLE支持MODIFY ORDER BY。 - DBE-14643:SQL Server 变量赋值期间不再出现 condition is always false(条件始终为 false)警告。
- DBE-12232:SQL Server 现已支持
CHANGETABLE。 - DBE-13312:SQL Server 现已支持
END CONVERSATION。 - DBE-12435:SQLite
PRAGMA_TABLE_INFO和PRAGMA_TABLE_XINFO表已正确解析。 - DBE-14997:PostgreSQL 将
CTE与INSERT INTO结合使用时,现在可以正确解析列。