DataGrip 2021.3 最新变化
DataGrip 2021.3 正式发布! 这是 2021 年的第三次重大更新,其中包含各种增强功能。 让我们看看它提供了什么新功能!
数据编辑器

聚合
我们增加了显示一系列单元的 Aggregate(聚合)视图的功能。 这是一项备受期待的功能,可帮助您管理数据并免除编写额外查询的需求! 这使数据编辑器更强大、更易用,也更接近 Excel 和 Google 电子表格。
选择要查看视图的单元范围,然后点击鼠标右键并选择 Show Aggregate View(显示聚合视图)。

基本信息:
- Aggregate(聚合)视图与 Value(值)视图共享面板,且分别拥有自己的标签页。 您可以将此面板移动到数据编辑器底部。
- 您可以使用齿轮图标在此视图中显示或隐藏任何聚合。
- 与提取器一样,聚合也是脚本。 除了我们默认捆绑的九个脚本之外,您还可以创建和共享自己的脚本。
- 聚合脚本和提取器可互换。 如果您之前使用提取器仅获取一个值,现在可以将其复制到 Aggregators 文件夹并用于聚合。 它与 Extractors 文件夹相同,位于 Scratches and consoles / Extensions / Database Tools and SQL(临时文件和控制台 / 扩展程序 / 数据库工具和 SQL)中。
状态栏会显示一个聚合值,您可以选择想要的值(总和、平均值、中值、最小值、最大值等)。

树节点的表视图
在任意架构节点上按 F4 即可显示节点内容的表视图。 例如,您可以获得架构中所有表的表视图:

或者,您也可以查看表列的表视图:
您可以使用此视图隐藏/显示列、将数据导出为多种格式,以及使用文本搜索。 另外,以下导航操作也适用:
- Ctrl+B 显示 DDL。
- F4 显示数据。
- Alt+Shift+B 在数据库树中高亮显示对象。

独立拆分
如果拆分编辑器后再次打开同一个表,则两个数据编辑器窗口现在将完全独立。 然后,您可以设置不同的筛选和排序选项,用于比较和处理数据。 筛选和排序先前是同步的,对操作来说不是很理想。

自定义字体
您可以在 Database | Data views | Use custom font(数据库 | 数据视图 | 使用自定义字体)下选择一种专用字体来显示数据。
通过多个值进行外键导航
在数据编辑器中,您现在可以选择多个值并导航到相关数据。
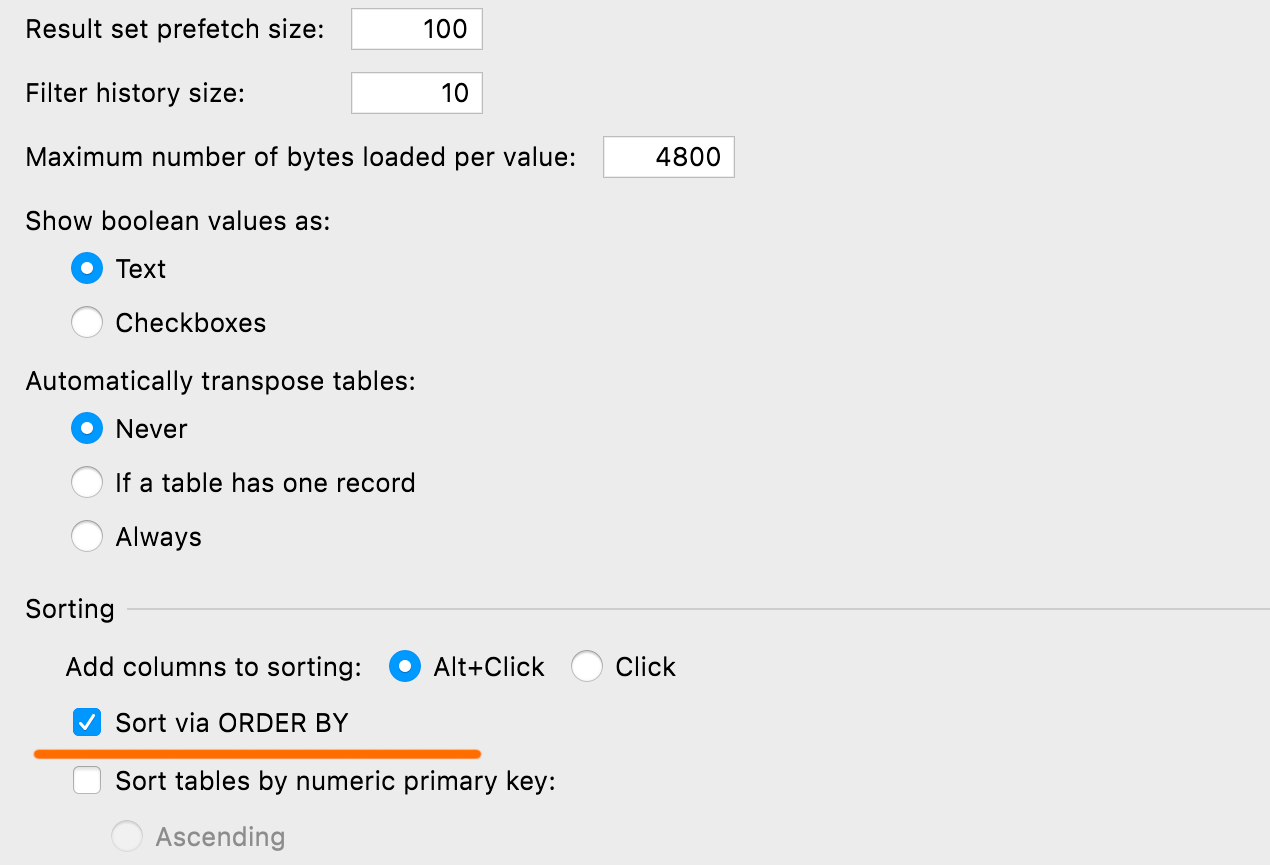
默认排序设置
您可以通过 ORDER BY 或 client-side 定义表格的默认排序方法:后者不运行任何新查询并且仅对当前页面进行排序。 该设置位于 Database | Data views | Sorting | Sort via ORDER BY(数据库 | 数据视图 | 排序 | 通过 ORDER BY 排序)中。
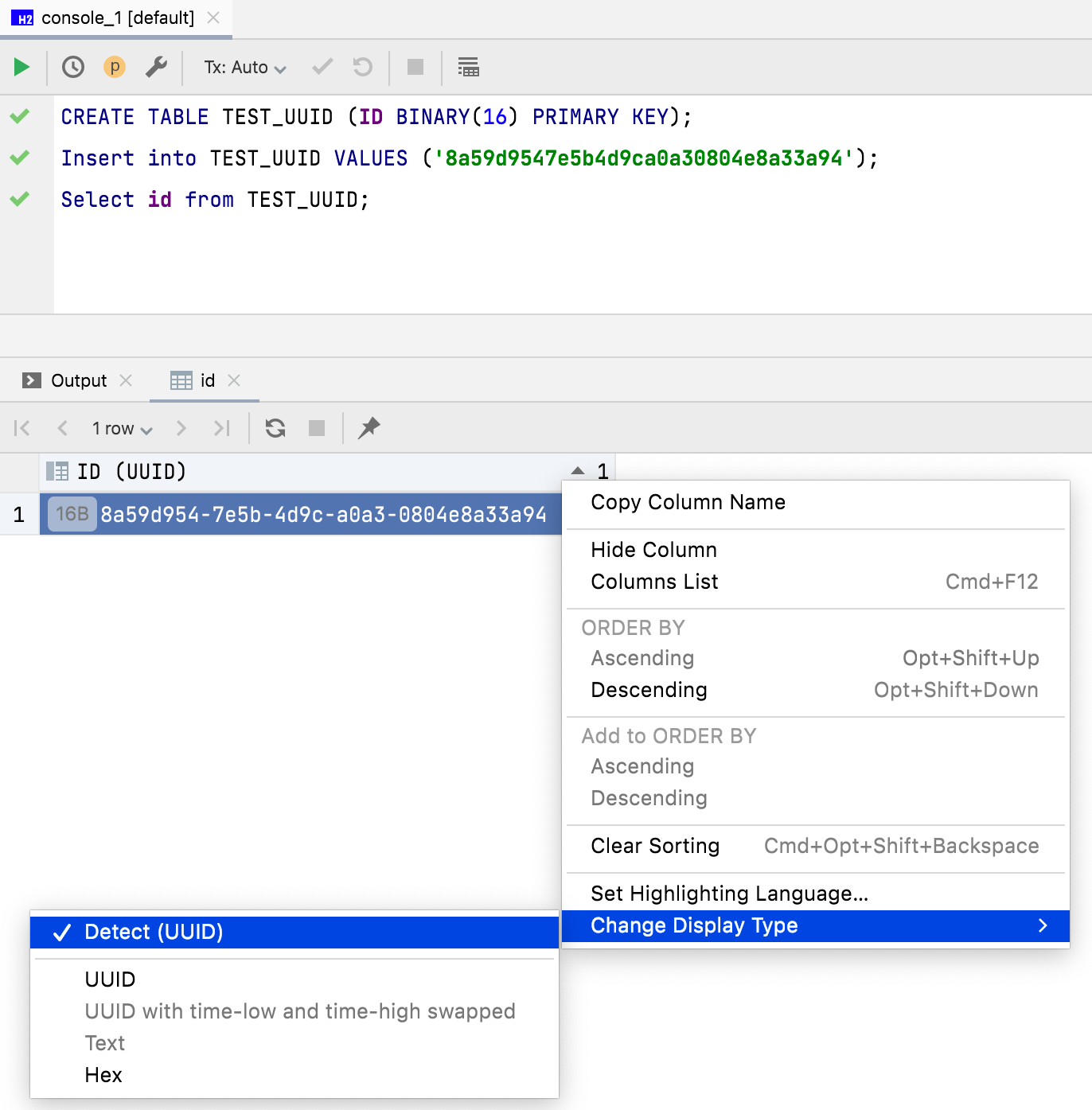
二进制数据的显示模式
16 字节数据现在默认显示为 UUID。 您也可以自定义二进制数据在数据编辑器列中的显示方式。
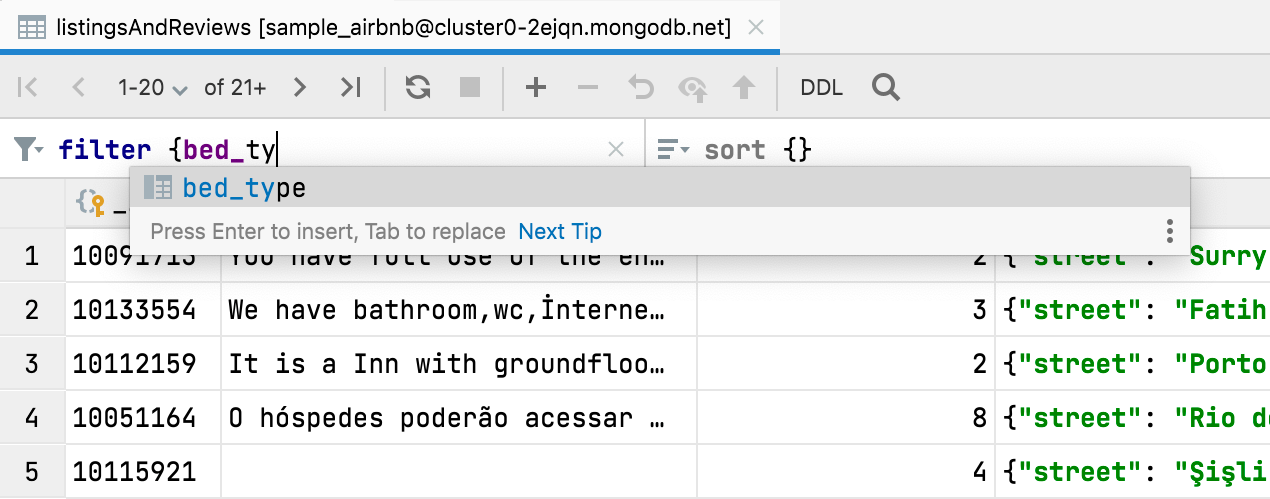
filter {} 和 sort {} 的补全 MongoDB
在 MongoDB 集合中筛选数据时,现在可以使用代码补全。
将数据库保留在 VCS 中

映射 DDL 数据源和真实数据源
上一版本引入了基于真实数据源生成 DDL 数据源的功能,此版本是其逻辑延续。 现在,此工作流已获得完全支持。 您可以:
- 从真实数据源生成 DDL 数据源:参阅 2021.2 公告。
- 将 DDL 数据源映射到真实数据源。
- 在两个方向上比较和同步。
请注意,DDL 数据源是一种虚拟数据源,其架构基于一组 SQL 脚本。 将这些文件存储在版本控制系统中即可将数据库保留在 VCS 下。
数据配置属性中新增了 DDL mappings(DDL 映射)标签页,用于定义映射到各 DDL 数据源的真实数据源。
如果您想进一步了解这些新功能在日常 VCS 流程中的作用,请阅读本文。

新的数据库差异窗口
要将您的 DDL 数据源与真实数据源比较和同步,请使用上下文菜单并从 DDL Mappings 子菜单中选择 Apply from...(应用自…)或者 Dump to...(转储至…)。

这一全新窗口具有更好的 UI,并且在右侧窗格中清楚显示了执行同步后您将获得的结果。

右侧窗格中的图例显示了不同颜色潜在结果的含义:
- 绿色和斜体:对象将被创建。
- 灰色:对象将被删除。
- 蓝色:对象将被更改。
Script preview(脚本预览)标签页显示结果脚本,可在新控制台中打开或从此对话框运行。 此脚本的结果是应用更改,使右侧数据库(目标)成为左侧数据库(源)的副本。
除了 Script preview(脚本预览)标签页,底部窗格中还有两个标签页:Object Properties Diff(对象属性差异)和 DDL Diff(DDL 差异)。 它们显示源数据库和目标数据库中对象的特定版本之间的差异。
注意:如果您只想比较两个架构或对象,应选择两者并按 Ctrl + D。
重要提示!差异查看器仍在全速开发中。 由于每个数据库都有自己的特定功能,部分对象可能会在显示上不同,但实际却相同。 这可能是因为类型别名或在生成中省略了默认属性。 如果您遇到此错误,请将其报告给我们的跟踪器。

文件相关操作
文件的所有操作也均可用于 DDL 数据源元素。 例如,您可以从数据库资源管理器中删除、复制或提交与架构元素相关的文件。
自动同步
打开此选项后,您的 DDL 数据源将随着相应文件的更改而自动刷新。 这是默认行为,但现在您可以选择将其禁用。
禁用后,源文件中的更改将不会自动反映在 DDL 数据源中,您需要点击 Refresh(刷新)进行应用。

设置默认架构和数据库
在 Default schemas/databases(默认架构/数据库)窗格中,您可以定义数据库和架构的名称,它们将在 DDL 数据源中显示。 DDL 脚本通常不包含名称,在这些情况下,默认会为数据库和架构设置虚拟名称。
连接性

意外空格警告
如果除 User(用户)或 Password(密码)之外的值有前导或尾随空格,DataGrip 将在您点击 Test Connection(测试连接)时发出警告。

LocalDB 作为专用数据源 SQL Server
SQL Server LocalDB 在驱动程序列表中有自己的专用驱动程序。 这意味着它具有单独类型的数据源,应该用于 LocalDB。 它的作用:
- LocalDB 连接可供进一步探索。
- 只要在驱动程序选项中为可执行文件设置一次路径,它就将应用于所有数据源。

Kerberos 身份验证 Oracle、SQL Server
现在可以在 Oracle 和 SQL Server 中使用 Kerberos 身份验证。 您需要使用 kinit 命令为主体获取初始票证授予票证,DataGrip 将在您选择 Kerberos 选项时使用该票证。

启用 DBMS_OUTPUT Oracle、IBM Db2
Options(选项)标签页中新增的这一选项允许您为新会话默认启用 DBMS_OUTPUT。

More options(更多选项)按钮
我们添加了一个 More Options(更多选项)按钮,为连接提供了更多配置选项。 当前选项包括为 Snowflake 连接添加 Schema(架构)和 Role(角色)字段,以及使 SSH 和 SSL 更易被发现的两个配置菜单项。

专家选项
Advanced(高级)标签页加入了一个 Expert options(专家选项)列表。 除了打开 JDBC 内省器的选项(请在使用前联系我们的支持团队!),还有以下数据库专用选项:
- Oracle:Disable incremental introspection(禁用增量内省)、Fetch LONG values(获取 LONG 值)和 <0>Introspect server objects(内省服务器对象)
- SQL Server:Disable incremental introspection(禁用增量内省)
- PostgreSQL(和类似选择):Disable incremental introspection(禁用增量内省)和 Do not use xmin in queries to pgdatabase(不在对 pgdatabase 的查询中使用 xmin)
- SQLite:Register REGEXP function(注册 REGEXP 函数)
- MYSQL:Use SHOW/CREATE for source code(为源代码使用 SHOW/CREATE)
- ClickHouse:Automatically assign sessionid(自动分配 sessionid)
内省
内省级别 Oracle
Oracle 用户经常遇到 DataGrip 的内省问题,在数据库和架构较多时会耗费很长时间。 内省流程可获取数据库元数据,例如对象名称和源代码。 DataGrip 需要它来提供快速的编码辅助、导航和搜索。
Oracle 系统目录较为缓慢,如果用户没有管理员权限,内省会更慢。 我们已经尽最大努力对获取元数据的查询做出了优化,但仍然有一些局限并非我们尽力就能左右。
我们了解到对于大多数日常工作,甚至对于有效的编码辅助来说,对象源其实都不需要加载。 在许多情况下,仅具有数据库对象名称就足以提供正确的代码补全和导航。 因此,我们为 Oracle 数据库引入了三个级别的内省:
- 级别 1:所有支持对象的名称及其签名,不包括索引列和私有软件包变量的名称
- 级别 2:除源代码外的所有内容
- 级别 3:所有内容
内省在级别 1 上最快,在级别 3 上最慢。

使用上下文菜单根据需要切换内省级别:

内省级别可针对架构或整个数据库设置。 架构从数据库继承内省级别,但也可独立设置。
内省级别由位于数据源图标旁的药丸状图标表示。 药丸越满,级别就越高。 蓝色图标表示内省级别为直接设置,灰色表示继承。

将链接服务器和数据库链接映射到数据源 SQL Server、Oracle
您可以将 SQL Server 中的链接服务器或 Oracle 中的数据库链接映射到任何现有数据源。

当外部对象被映射到数据源时,代码补全和解析将适用于使用这些外部对象的查询。

隐藏系统架构和模板数据库 PostgreSQL
内部系统架构(如 pg_toast 或 pg_temp)和模板数据库过去在架构列表中隐藏。 现在可通过 Schemas(架构)标签页中的相应选项显示。

支持流 Snowflake
现在,除了表和视图之外,流也会显示在数据库视图中。

分布式表 ClickHouse
分布式表现在位于数据库资源管理器中的专用节点下。
查询控制台

布尔表达式检查
One of our users posted about an unfortunate situation: he executed the UPDATE query on a production database with the condition WHERE id - 3727 (instead of =) and had millions of records updated!
我们也没想到 MySQL 会允许这样的情况发生,但世事就是如此难料。 当然,发现这个问题后,我们 DataGrip 团队就为此添加了一项检查。 接下来就请了解 WHERE 和 HAVING 子句中布尔表达式的检查。
如果表达式似乎不是明确的布尔值,DataGrip 会将其高亮显示为黄色,并在您运行此类查询之前发出警告。 它适用于 ClickHouse、Couchbase、Db2、H2、Hive/Spark、MySQL/MariaDB、Redshift、SQLite 和 Vertica。 在所有其他数据库中,这将被高亮显示为错误。

提取查询的函数
现在,查询可以被提取为表函数。 为此,首先选择查询,调用 Refactor(重构)菜单,然后使用 Extract Routine(提取例程)。

JOIN 基数嵌入提示
新的嵌入提示将说明 JOIN 子句的基数。 三种可能的选项是:一对一、一对多和多对多。 如果您想将其关闭,可以调整 Preferences | Editor | Inlay Hints | Join cardinality(偏好设置 | 编辑器 | 嵌入提示 | Join 基数)中的设置。

数据库名称的代码补全 MongoDB
使用 getSiblingDB 补全数据库名称,使用 getCollection 补全集合名称。
此外,如果是从通过 getCollection 定义的集合中使用字段名称,字段名称会被补全和解析。
Services(服务)工具窗口

输出中的时间戳默认隐藏
根据此请求,默认不再为查询输出显示时间戳。 如果要恢复先前的行为,可以在 Database | General | Show timestamp for query output(数据库 | 常规 | 为查询输出显示时间戳)中调整设置。

新激活设置
如果在窗口模式下使用 Services(服务)工具窗口,它默认将被隐藏在 IDE 之后。 使用新设置,可在每次运行查询时向其转移焦点,让它在查询完成后出现。
此外,如果您在其他控制台中完成较长的查询时感觉会受到干扰,可激活 Services(服务)工具窗口中的相应标签页,选中 Activate Services output pane for selected query console only(仅为所选查询控制台激活“服务”输出窗格)复选框。
导入/导出

新的数据导入 UI
导入 .csv 文件或复制表/结果集时,您将看到以下改进:
- 您可以选择现有表或创建新表。
- 您可以在导入对话框中更改目标架构。 如果复制表或结果集,则不会出现目标的专用对话框。
- 目标被保存为每个架构的默认值。 因此,如果您是持续从一个特定架构复制到另一个架构,则无需每次都选择目标。

First row is header(第一行是标题)自动检测
当您打开或导入 CSV 文件时,DataGrip 会自动检测第一行是否为标题以及是否包含列名称。

CSV 文件中的自动列类型
DataGrip 现在可以检测 CSV 文件中的列类型。 这可以让您按数值对数据进行排序。 过去,它们会被视为文本,排序不够直观。
其他

新的 Bookmarks(书签)工具窗口
我们以前有两个非常相似的实例:Favorites(收藏夹)和 Bookmarks(书签)。 由于两者之间的区别有时会造成困惑,我们决定改为只使用 Bookmarks(书签)。 我们重新设计了此功能的工作流,并为其创建了一个新的工具窗口。
从现在开始,您标记为重要(在 macOS 上使用 F3,在 Windows/Linux 上使用 F11)的所有对象或文件都将位于新的 Bookmarks(书签)工具窗口中。